
Cómo desarrollar una aplicación semejante a un robot de indexación de páginas web. Mostramos cómo realizar una aplicación en Borland Delphi 6 y base de datos Paradox para acceder a páginas web (especificando la URL o la IP), obtener el contenido HTML y guardarlo en una base de datos. Es el fundamento de los motores de búsqueda como Google, Bing, Yahoo, etc.
- Robot de indexación de contenidos web.
- Cómo hacer un robot de indexación de contenidos web casero con Delphi y Paradox.
- AjpdSoft Capturador de páginas web en funcionamiento – Código fuente completo gratuito en Delphi 6.
- Anexo.
Robot de indexación de contenidos web
Un robot de indexación de contenidos web suele ser un conjunto de equipos informáticos, en el caso de buscadores como Google, Yahoo, Bing suelen ser miles e incluso cientos de miles, que están continuamente buscando páginas web mediante varios mecanismos (recorriendo IP, recorriendo URL de otros sitios web ya indexados, a petición del usuario, etc. Obtienen el contenido de dichas páginas web y lo almacenan en una base de datos. De esta forma cuando el usuario introduce alguna palabra o palabras en un buscador, este accede a su base de datos y muestra los resultados por relevancia.
El proceso de un robot es un poco más complejo de lo indicado anteriormente, si bien su tarea principal es la de capturar y almacenar información para futuras búsquedas.
Existen muchos tipos de robot en función del tipo de buscador que los implemente. A continuación mostramos las características principales de los buscadores jerárquicos (arañas o spiders) que suelen ser los que usan los robots para retroalimentar sus bases de datos:
- Las arañas (también llamadas «spiders») de los motores de búsqueda, recorren las páginas recopilando información sobre los contenidos de las páginas. Cuando se busca una información concreta en los buscadores, ellos consultan su base de datos y presentan resultados clasificados por su relevancia para esa búsqueda concreta. Los buscadores pueden almacenar en sus bases de datos desde la página de entrada de cada web, hasta todas las páginas que residan en el servidor, una vez que las arañas (spiders) las hayan reconocido e indexado.
- Si se busca una palabra, en los resultados que ofrecerá el motor de búsqueda aparecerán páginas que contengan esta palabra en alguna parte de su texto de contenido.
- Si consideran que un sitio web es importante para el usuario, tienden a registrar todas sus páginas. Si no la consideran importante, no se almacenan todas.
- Cada cierto tiempo, los motores revisan los sitios web, para actualizar los contenidos de su base de datos, por tanto puede que los resultados de la búsqueda estén desactualizados.
- Los buscadores jerárquicos tienen una colección de programas simples y potentes con diferentes cometidos. Se suelen dividir en tres partes. Los programas que exploran la red -arañas (spiders)-, los que construyen la base de datos y los que utiliza el usuario, el programa que explota la base de datos.
- Si se paga, se puede aparecer en las primeras posiciones de resultados, aunque los principales buscadores delimitan estos resultados e indican al usuario que se trata de anuncios (resultados esponsorizados o patrocinados). Hasta el momento, aparentemente, esta forma de publicidad es indicada explícitamente. Los buscadores jerárquicos se han visto obligados a comercializar este tipo de publicidad para poder seguir ofreciendo a los usuarios el servicio de forma gratuita.
Cómo hacer un robot de indexación de contenidos web casero con Delphi y Paradox
A continuación mostramos los pasos para desarrollar una aplicación que accederá a las páginas web previamente indicadas (por URL o por rango de IP), obtendrá su contenido HTML y lo guardará en base de datos para su posterior explotación.
Crear tabla en base de datos Paradox para almacenar las páginas web indexadas con Database Desktop
En primer lugar crearemos la tabla de la base de datos Paradox que contendrá la información capturada o indexada por la aplicación. Dicha tabla «capturas.DB» está disponible ya creada en la descarga gratuita de la aplicación completa con código fuente AjpdSoft Capturador de páginas web.
Si queremos crearla manualmente, usaremos Borland Database Desktop, una aplicación «antigua» pero aún funcional que nos permitirá crear tablas Paradox. Podemos descargarla desde la URL:
No necesita instalación, la descargaremos desde la URL anterior, descomprimiremos el fichero «bdd.zip» y ejecutaremos el fichero «DBD32.EXE», en equipos con Windows Vista, Windows 7 y Windows 8 puede mostrar un mensaje como el siguiente, pulsaremos en «Ejecutar programa»:
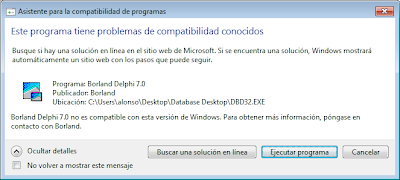
Con el texto: Asistente para la compatibilidad de programas. Este programa tiene problemas de compatibilidad conocidos. Busque si hay una solución en línea en el sitio web de Microsoft. Si se encuentra una solución, Windows mostrará automáticamente un sitio web con los pasos que puede seguir. Borland Delphi 7.0 no es compatible con esta versión de Windows. Para obtener más información póngase en contacto con Borland.
Nos mostrará otro error que aceptaremos pulsando en «Aceptar»:
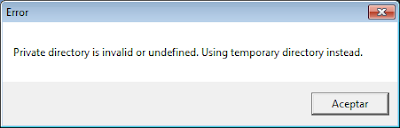
Con el texto: Private directory is invalid or undefined. Using temporary directory instead.
Si nos aparece este otro error:
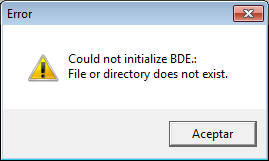
Con el texto: Could not initialize BDE. File or directory does not exist.
Es debido a que o bien no tenemos instalado el BDE (Borland Database Engine) o bien estamos ejecutando la aplicación Borland Database Desktop en una carpeta y subcarpeta demasiado larga, en este caso copiaremos la carpeta de Database Desktop a una carpeta del tipo:
C:/DatabaseDesktop
Si no tenemos instalado el BDE (Borland Database Engine) podremos instalarlo siguiendo los pasos de este tutorial:
Una vez abierto Database Desktop, pulsaremos en el menú «File» – «New» – «Table»:
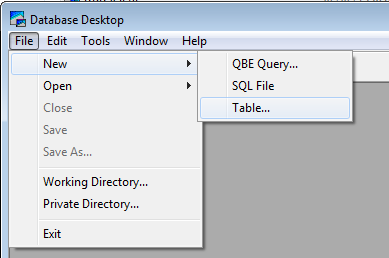
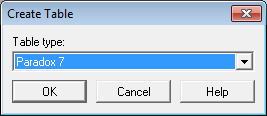
Elegiremos «Paradox 7» en «Table type» y pulsaremos «OK»:
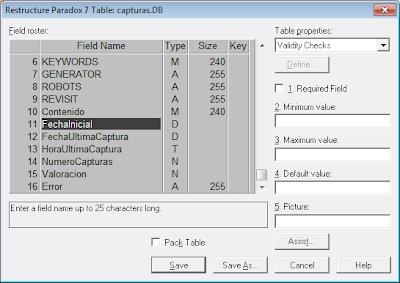
Añadiremos todos los campos para la tabla «capturas.DB» con su tipo de datos, como se muestra en las dos imágenes siguientes:

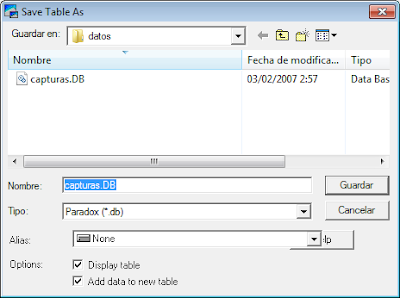
Guardaremos pulsando en «Save As»:
Indicaremos la carpeta y nombre del fichero que contendrá la tabla para almacenar las web indexadas, en nuestro caso «capturas.DB»:
Nota: la tabla «capturas.DB» está disponible ya creada en la descarga gratuita de la aplicación completa con código fuente AjpdSoft Capturador de páginas web.
Desarrollar aplicación Delphi para indexar páginas web y almacenar el HTML en base de datos Paradox
Abriremos Delphi 6, crearemos un nuevo proyecto de tipo Application, desde el menú «File» – «New» – «Application». Esta aplicación completa con código fuente está disponible gratuitamente en la descarga:
En el primer formulario que se crea automáticamente añadiremos los siguientes componentes:
- PageControl: contenedor para albergar el resto de componentes en pestañas o solapas.
En la primera pestaña del PageControl, en «Capturar» añadiremos los siguientes componentes:
- Button: para «Iniciar captura» y para «Cancelar captura».
- Memo: para mostrar el log de resultados de indexación de páginas.
- ProgressBar: para mostrar el progreso de la indexación.
- StatusBar: para mostrar algunos resultados e información de progreso.

En la segunda pestaña del PageControl, «Configurar», añadiremos los siguientes componentes:
- CheckBox: para la pestaña de configuración, para establecer el método de búsqueda de sitios web, por IP, por URL, para guardar log con el resultado y para volver a capturar las páginas ya indexadas en base de datos.
- Edit: para introducir la IP desde y la IP hasta a recorrer por el indexador.
- Memo: para almacenar las páginas web a capturar o indexar.

En la tercera solapa o pestaña del PageControl, «Datos capturados» añadiremos los siguientes componentes:
- DBNavigator: barra de botones que irá enlazada con la tabla «capturas» para desplazarnos por los registros (siguiente, anterior, primero, último, eliminar, editar, refrescar, cancelar).
- DBGrid: para mostrar los datos indexados en la tabla «capturas» en una rejilla de datos.
- Button: para «Abrir BD», «Visualizar HTML» y «Visualizar».
- Table, DataSource, Query: componentes no visibles para enlace con tabla «capturas» y para inserción de registro nuevo.

Enlazaremos los componentes de acceso a base de datos Paradox no visuales entre ellos, los Table con los DataSource mediante la propiedad DataSet del DataSource:
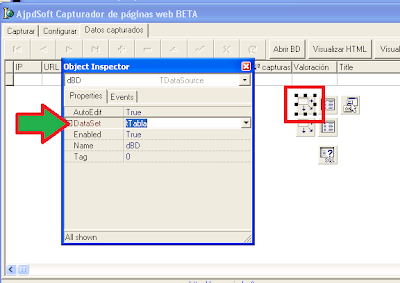
En los Table, en la propiedad DatabaseName añadiremos la ubicación (ruta, carpeta) donde guardaremos el fichero «capturas.db» con la tabla creada anteriormente. En la propiedad TableName de los Table indicaremos el nombre del fichero «capturas.DB». De esta forma enlazaremos los componentes no visuales a la tabla Paradox:
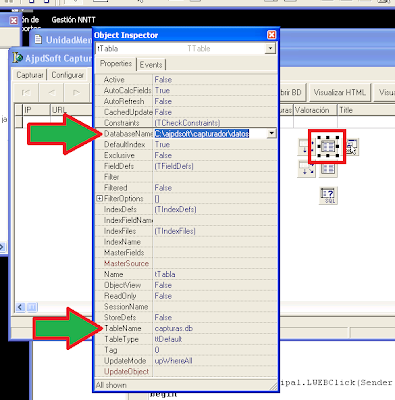
Pulsando sobre el Table con el botón derecho del ratón y seleccionando «Fields Editor» podremos añadir los campos de la tabla «capturas»:

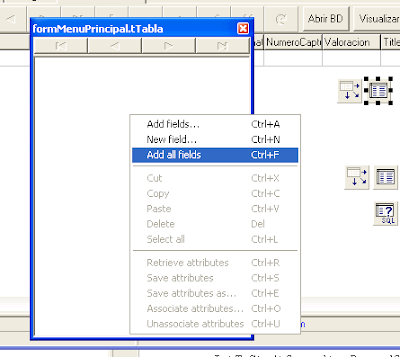
Pulsaremos con el botón derecho sobre la ventana que se abre y seleccionaremos «Add all fields»:
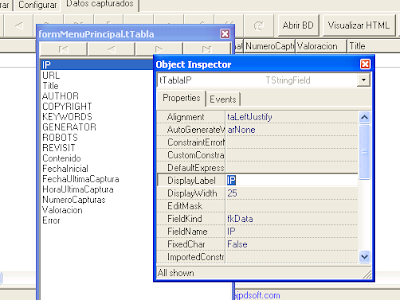
Una vez añadidos los campos podremos editar sus propiedades y establecer el DisplayLabel (título) y el DisplayWidth (tamaño):
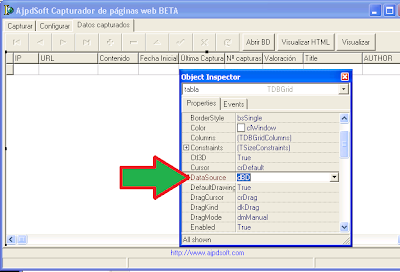
Por último enlazaremos los componentes visuales DBNavigator y DBGrid a los no visuales de acceso a datos mediante la propiedad DataSource del DBGrid y del DBNavigator:
Pulsando con el botón derecho del ratón sobre el DBGrid y eligiendo «Add All Fields»:
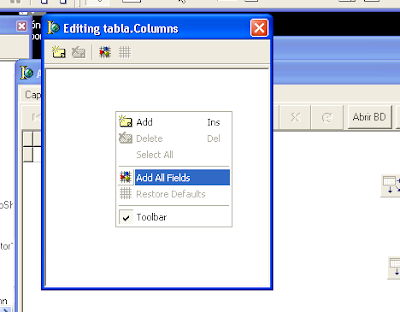
De esta forma quedarán los campos añadidos al DBGrid y podremos elegir en qué posición aparecerán y lo que queramos ocultar o mostrar:
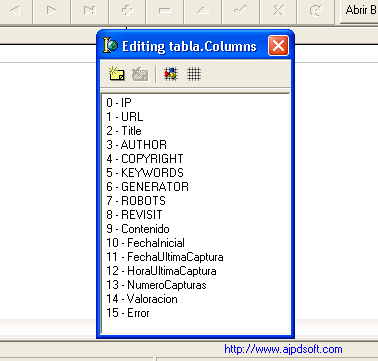
Añadiremos una unidad donde introduciremos los procedimientos de captura de página web mediante TidHTTP y otros que necesitaremos para la aplicación, para ello pulsaremos en el menú «File» – «New» – «Unit»:

Introduciremos el nombre para la nueva unidad y la guardaremos. Añadiremos el código fuente que indicamos aquí:
Añadiremos también un formulario para mostrar el código HTML indexado del registro seleccionado, para ello pulsaremos en «File» – «New» – «Form»:

Este formulario solo contendrá un Memo donde mostraremos el contenido HTML de una web indexada:
El código fuente de la unidad principal está disponible aquí. Y la descarga de la aplicación completa con el código fuente gratuito en Delphi 6:
AjpdSoft Capturador de páginas web en funcionamiento – Código fuente completo gratuito en Delphi 6
A continuación mostramos el funcionamiento de AjpdSoft Capturador de páginas web, en primer lugar en la pestaña «Configurar» deberemos especificar el rango de IPs a indexar o bien las URL a indexar o ambos métodos a la vez:

Una vez especificadas las URL/IP en la pestaña «Capturar» pulsaremos en «Iniciar captura», la aplicación AjpdSoft Capturador de páginas web navegará a cada URL/IP especificada y obtendrá el contenido HTML y lo guardará en una base de datos:
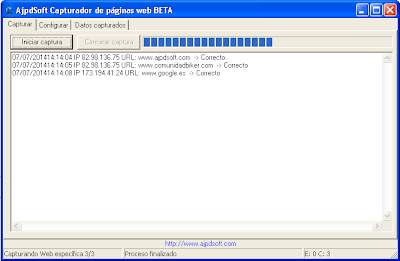
En la pestaña «Datos capturados», pulsando «Abrir BD», podremos consultar los datos capturados/indexados por AjpdSoft Capturador de páginas web:

Si queremos ver el contenido HTML capturado de un registro concreto lo seleccionaremos y pulsaremos en «Visualizar HTML». Si queremos visualizar el HTML en un navegador web pulsaremos en «Visualizar»:

Como vemos, AjpdSoft Capturador de páginas web, es un sencillo ejemplo de cómo desarrollar una aplicación similar a un robot de indexación de páginas web como los usados por Google, Yahoo, Bing, etc. Esta aplicación servirá de ejemplo para desarrolladores. Está en fase Beta y está descontinuada, pero es útil para realizar pruebas y como base para realizar otras aplicaciones.
Anexo
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
unit UnidadProcedimientos; interface function ObtenerWeb(webIP : string) : string; function obtenerURLdeIP (ip : string) : string; function obtenerEtiqueta (contenidoWeb : string; etiquetaIni : string; etiquetaFin : string) : string; function obtenerIPdeURL (url : string) : string; var errorCaptura : string; numErrores : double; numAciertos : double; implementation uses IdHTTP, Classes, Sockets, SysUtils; //Obtener IP pública pc local function ObtenerWeb(webIP : string) : string; var obtenerHTTP : TidHTTP; web : TStringList; begin errorCaptura := ''; web := TStringList.Create; obtenerHTTP := TidHTTP.Create(nil); try web.Text := obtenerHTTP.Get('http://' + webIP); numAciertos := numAciertos + 1; except on e: exception do begin errorCaptura := e.Message; numErrores := numErrores + 1; obtenerHTTP.Free; end; end; ObtenerWeb := web.Text; end; function obtenerTagWeb (contenido : string) : string; begin // end; //obtiene la URL de una IP function obtenerURLdeIP (ip : string) : string; var ctURL : TTcpServer; begin ctURL := TTCPServer.Create (nil); obtenerURLdeIP := ctURL.LookupHostName (ip); end; //obtiene la IP de una URL function obtenerIPdeURL (url : string) : string; var ctURL : TTcpServer; begin ctURL := TTCPServer.Create (nil); obtenerIPdeURL := ctURL.LookupHostAddr (url); end; function obtenerEtiqueta (contenidoWeb : string; etiquetaIni : string; etiquetaFin : string) : string; var lineas : TStringList; i : integer; titulo, lineaActual : string; begin lineas := TStringList.Create; lineas.Text := contenidoWeb; titulo := ''; etiquetaIni := AnsiUpperCase(etiquetaIni); etiquetaFin := AnsiUpperCase(etiquetaFin); for i := 0 to lineas.Count - 1 do begin lineaActual := lineas.Strings[i]; //si encuentra las dos etiquetas en la misma línea if (Pos (etiquetaIni, AnsiUpperCase(lineaActual)) <> 0) and (Pos (etiquetaFin, AnsiUpperCase(lineaActual)) <> 0)then begin titulo := copy (lineaActual, Pos (etiquetaIni, AnsiUpperCase(lineaActual)) + length (etiquetaIni), Pos (etiquetaFin, AnsiUpperCase(lineaActual)) - length (etiquetaFin) - 1); Break; end; //si en la línea sólo aparece el inicio del título if (Pos (etiquetaIni, AnsiUpperCase(lineaActual)) <> 0) and (Pos (etiquetaFin, AnsiUpperCase(lineaActual)) = 0)then begin titulo := copy (lineaActual, Pos (etiquetaIni, AnsiUpperCase(lineaActual)), length(lineaActual)); end; //si en la línea sólo aparece el fin del título if (Pos (etiquetaIni, AnsiUpperCase(lineaActual)) = 0) and (Pos (etiquetaFin, lineaActual) <> 0)then begin titulo := titulo + copy (lineaActual, Pos (etiquetaFin, AnsiUpperCase(lineaActual)), length(lineaActual)); break; end; end; obtenerEtiqueta := titulo; end; end. |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 |
unit UnidadMenuPrincipal; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, Dialogs, StdCtrls, ComCtrls, ActnList, DB, DBTables, ExtCtrls, DBCtrls, IdBaseComponent, IdComponent, shellapi, Grids, DBGrids; type TformMenuPrincipal = class(TForm) PageControl1: TPageControl; TabSheet1: TTabSheet; TabSheet2: TTabSheet; TabSheet3: TTabSheet; be: TStatusBar; GroupBox1: TGroupBox; GroupBox2: TGroupBox; bIniciarCaptura: TButton; ActionList1: TActionList; actIniciarCaptura: TAction; tTabla: TTable; dBD: TDataSource; tTablaIP: TStringField; tTablaURL: TStringField; tTablaContenido: TMemoField; tTablaFechaInicial: TDateField; tTablaFechaUltimaCaptura: TDateField; tTablaNumeroCapturas: TFloatField; tTablaValoracion: TFloatField; tTablaTitle: TStringField; tTablaAUTHOR: TStringField; tTablaCOPYRIGHT: TStringField; tTablaKEYWORDS: TMemoField; tTablaGENERATOR: TStringField; tTablaROBOTS: TStringField; tTablaREVISIT: TStringField; Label6: TLabel; txtD1: TEdit; Label3: TLabel; txtD2: TEdit; Label5: TLabel; txtD3: TEdit; Label7: TLabel; txtD4: TEdit; txtH4: TEdit; Label11: TLabel; txtH3: TEdit; Label10: TLabel; txtH2: TEdit; Label9: TLabel; txtH1: TEdit; Label8: TLabel; txtWebEspecificas: TMemo; tTablaHoraUltimaCaptura: TTimeField; tTablaError: TStringField; tTablaInsertar: TTable; dBDInsertar: TDataSource; tTablaInsertarIP: TStringField; tTablaInsertarURL: TStringField; tTablaInsertarTitle: TStringField; tTablaInsertarAUTHOR: TStringField; tTablaInsertarCOPYRIGHT: TStringField; tTablaInsertarKEYWORDS: TMemoField; tTablaInsertarGENERATOR: TStringField; tTablaInsertarROBOTS: TStringField; tTablaInsertarREVISIT: TStringField; tTablaInsertarContenido: TMemoField; tTablaInsertarFechaInicial: TDateField; tTablaInsertarFechaUltimaCaptura: TDateField; tTablaInsertarHoraUltimaCaptura: TTimeField; tTablaInsertarNumeroCapturas: TFloatField; tTablaInsertarValoracion: TFloatField; tTablaInsertarError: TStringField; opCapturarEspecificas: TCheckBox; opCapturarIPs: TCheckBox; Button1: TButton; actCancelarCaptura: TAction; Panel1: TPanel; Panel2: TPanel; Panel3: TPanel; DBNavigator1: TDBNavigator; Button2: TButton; tConsulta: TQuery; bp: TProgressBar; actAbrirBD: TAction; tabla: TDBGrid; actVisualizar: TAction; actVisualizarHTML: TAction; Button3: TButton; Button4: TButton; GroupBox4: TGroupBox; opGuardarLog: TCheckBox; opCapturarBD: TCheckBox; txtLog: TMemo; LWEB: TLabel; procedure actIniciarCapturaExecute(Sender: TObject); procedure txtD1Change(Sender: TObject); procedure txtD1KeyPress(Sender: TObject; var Key: Char); procedure txtD2Change(Sender: TObject); procedure txtD2KeyPress(Sender: TObject; var Key: Char); procedure txtD3Change(Sender: TObject); procedure txtD3KeyPress(Sender: TObject; var Key: Char); procedure txtD4Change(Sender: TObject); procedure txtD4KeyPress(Sender: TObject; var Key: Char); procedure txtH4Exit(Sender: TObject); procedure txtH4KeyPress(Sender: TObject; var Key: Char); procedure insertarWeb (webCaptura : string; IPCaptura : string); procedure FormCreate(Sender: TObject); procedure FormClose(Sender: TObject; var Action: TCloseAction); procedure actCancelarCapturaExecute(Sender: TObject); procedure actAbrirBDExecute(Sender: TObject); procedure actVisualizarExecute(Sender: TObject); procedure actVisualizarHTMLExecute(Sender: TObject); procedure LWEBClick(Sender: TObject); private { Private declarations } cancelarProceso : boolean; public { Public declarations } end; var formMenuPrincipal: TformMenuPrincipal; implementation uses UnidadProcedimientos, UnidadVisualizador, UnidadVisualizacion; {$R *.dfm} procedure TformMenuPrincipal.insertarWeb (webCaptura : string; IPCaptura : string); var contenidoWeb : string; eqTitle, eqKeywords, eqCopyright : string; numero : double; begin contenidoWeb := ObtenerWeb(webCaptura); if contenidoWeb <> '' then begin if tTablaInsertar.Locate('IP', IPCaptura, []) then begin tTablaInsertar.edit; if not varisnull(tTablaInsertarNumeroCapturas.Value) then begin numero := tTablaInsertarNumeroCapturas.value; numero := numero + 1; tTablaInsertarNumeroCapturas.Value := numero; end else tTablaInsertarNumeroCapturas.Value := 1; end else begin tTablaInsertar.Insert; tTablaInsertarNumeroCapturas.Value := 1; tTablaInsertarIP.Value := IPCaptura; end; eqTitle := obtenerEtiqueta (contenidoWeb, ''); eqKeywords := obtenerEtiqueta (contenidoWeb, ''); eqCopyright := obtenerEtiqueta (contenidoWeb, ''); tTablaInsertarURL.Value := webCaptura; tTablaInsertarContenido.Value := contenidoWeb; tTablaInsertarFechaInicial.Value := date; tTablaInsertarFechaUltimaCaptura.Value := date; tTablaInsertarHoraUltimaCaptura.Value := time; tTablaInsertarTitle.Value := eqTitle; tTablaInsertarKEYWORDS.Value := eqKeywords; tTablaInsertarCOPYRIGHT.Value := eqCopyright; tTablaInsertarError.Value := errorCaptura; tTablaInsertar.Post; end else begin if tTablaInsertar.Locate('IP', IPCaptura, []) then tTablaInsertar.edit else tTablaInsertar.Insert; tTablaInsertarIP.Value := IPCaptura; tTablaInsertarURL.Value := webCaptura; tTablaInsertarContenido.Value := ''; tTablaInsertarFechaInicial.Value := date; tTablaInsertarFechaUltimaCaptura.Value := date; tTablaInsertarHoraUltimaCaptura.Value := time; tTablaInsertarTitle.Value := ''; tTablaInsertarKEYWORDS.Value := ''; tTablaInsertarError.Value := errorCaptura; tTablaInsertar.Post; end; end; procedure TformMenuPrincipal.actIniciarCapturaExecute(Sender: TObject); var i : integer; ipCapturar, url : string; begin cancelarProceso := false; numErrores := 0; numAciertos := 0; actCancelarCaptura.Enabled := true; if opCapturarBD.Checked then begin tTablaInsertar.Open; tConsulta.Close; tConsulta.SQL.Clear; tConsulta.SQL.Add('SELECT URL, IP FROM Capturas'); tConsulta.Open; bp.Min := 1; bp.Max := tConsulta.RecordCount; while not tConsulta.Eof do begin Application.ProcessMessages; bp.Position := tConsulta.RecNo; bp.Refresh; be.Panels[0].Text := 'Capturando Web BD ' + inttostr(tConsulta.RecNo) + '/' + IntToStr(tConsulta.RecordCount); be.Refresh; if cancelarProceso then Break; if not varisnull(tConsulta.fieldbyname('URL').Value) then url := tConsulta.fieldbyname('URL').Value else url := ''; ipCapturar := tConsulta.fieldbyname('IP').Value; if url <> '' then begin if Pos ('http://', url) <> 0 then url := copy (url, 8, length (url)); if Pos ('https://', url) <> 0 then url := copy (url, 9, length (url)); if url <> '' then begin be.panels[1].text := 'Obteniendo contenido web: ' + url; be.Refresh; ipCapturar := obtenerIPdeURL (url); if ipCapturar <> '' then begin insertarWeb (url, ipCapturar); if errorCaptura <> '' then txtLog.Lines.Add(datetostr(date) + timetostr(time) + ' IP ' + ipCapturar + ' URL: ' + url + ' -> Error: ' + errorCaptura) else txtLog.Lines.Add(datetostr(date) + timetostr(time) + ' IP ' + ipCapturar + ' URL: ' + url + ' -> Correcto'); be.Panels[2].Text := 'E: ' + floattostr(numErrores) + ' C: ' + floattostr(numAciertos); be.Refresh; end; end; end; tConsulta.Next; end; end; if opCapturarIPs.Checked then begin tTablaInsertar.Open; if txtD1.Text <> '' then begin //obtenemos las webs del rango de ips especificado for i := strtoint(txtD4.Text) to strtoint (txtH4.Text) do begin Application.ProcessMessages; //be.Panels[0].Text := 'Capturando IP ' + inttostr() + // IntToStr(tConsulta.RecordCount); //be.Refresh; if cancelarProceso then Break; ipCapturar := txtD1.Text + '.' + txtD2.Text + '.' + txtD3.Text + '.' + IntToStr(i); be.panels[1].text := 'Obteniendo contenido web: ' + ipCapturar; be.Refresh; if ipCapturar <> '' then begin be.panels[1].text := 'Obteniendo contenido web: ' + ipCapturar; be.Refresh; url := ''; url := obtenerURLdeIP(ipCapturar); be.panels[1].text := 'Obteniendo contenido web: ' + url; be.Refresh; insertarWeb (url, ipCapturar); if errorCaptura <> '' then txtLog.Lines.Add(datetostr(date) + timetostr(time) + ' IP ' + ipCapturar + ' URL: ' + url + ' -> Error: ' + errorCaptura) else txtLog.Lines.Add(datetostr(date) + timetostr(time) + ' IP ' + ipCapturar + ' URL: ' + url + ' -> Correcto'); be.Panels[2].Text := 'E: ' + floattostr(numErrores) + ' C: ' + floattostr(numAciertos); be.Refresh; end; end; end; end; //obtenemos las webs de las URLs especificadas if opCapturarEspecificas.Checked then begin bp.Min := 1; bp.Max := txtWebEspecificas.Lines.Count; tTablaInsertar.Open; for i := 0 to txtWebEspecificas.Lines.Count - 1 do begin Application.ProcessMessages; be.Panels[0].Text := 'Capturando Web específica ' + inttostr(i + 1) + '/' + IntToStr(txtWebEspecificas.Lines.Count); be.Refresh; bp.Position := i; if cancelarProceso then Break; url := txtWebEspecificas.Lines.Strings[i]; if Pos ('http://', url) <> 0 then url := copy (url, 8, length (url)); if Pos ('https://', url) <> 0 then url := copy (url, 9, length (url)); if url <> '' then begin be.panels[1].text := 'Obteniendo contenido web: ' + url; be.Refresh; ipCapturar := obtenerIPdeURL (url); if ipCapturar <> '' then begin insertarWeb (url, ipCapturar); if errorCaptura <> '' then txtLog.Lines.Add(datetostr(date) + timetostr(time) + ' IP ' + ipCapturar + ' URL: ' + url + ' -> Error: ' + errorCaptura) else txtLog.Lines.Add(datetostr(date) + timetostr(time) + ' IP ' + ipCapturar + ' URL: ' + url + ' -> Correcto'); be.Panels[2].Text := 'E: ' + floattostr(numErrores) + ' C: ' + floattostr(numAciertos); be.Refresh; end; end; end; end; if opGuardarLog.checked then txtLog.Lines.savetofile(extractfilepath(application.exename) + 'log.txt'); be.panels[1].text := 'Proceso finalizado'; actCancelarCaptura.Enabled := false; end; procedure TformMenuPrincipal.txtD1Change(Sender: TObject); begin try if Length(txtD1.Text) = 3 then txtD2.SetFocus; txtH1.Text := txtD1.Text; except end; end; procedure TformMenuPrincipal.txtD1KeyPress(Sender: TObject; var Key: Char); begin if key = '.' then begin txtD2.SetFocus; Key := chr(0); end; end; procedure TformMenuPrincipal.txtD2Change(Sender: TObject); begin try if Length(txtD2.Text) = 3 then txtD3.SetFocus; txtH2.Text := txtD2.Text; except end; end; procedure TformMenuPrincipal.txtD2KeyPress(Sender: TObject; var Key: Char); begin if key = '.' then begin txtD3.SetFocus; Key := chr(0); end; end; procedure TformMenuPrincipal.txtD3Change(Sender: TObject); begin try if Length(txtD3.Text) = 3 then txtD4.SetFocus; txtH3.Text := txtD3.Text; except end; end; procedure TformMenuPrincipal.txtD3KeyPress(Sender: TObject; var Key: Char); begin if key = '.' then begin txtD4.SetFocus; Key := chr(0); end; end; procedure TformMenuPrincipal.txtD4Change(Sender: TObject); begin try if Length(txtD4.Text) = 3 then txtH4.SetFocus; txtH4.Text := txtD4.Text; except end; end; procedure TformMenuPrincipal.txtD4KeyPress(Sender: TObject; var Key: Char); begin if key = '.' then begin txtH4.SetFocus; Key := chr(0); end; end; procedure TformMenuPrincipal.txtH4Exit(Sender: TObject); begin if StrToInt(txtH4.Text) < StrToInt(txtD4.Text) then begin MessageDlg ('La IP desde la que desee hacer ping no puede ser menor ' + 'que la IP hasta la que desee hacer ping', mtWarning, [mbok], 0); txtH4.SetFocus; end; end; procedure TformMenuPrincipal.txtH4KeyPress(Sender: TObject; var Key: Char); begin if key = '.' then begin Key := chr(0); end; end; procedure TformMenuPrincipal.FormCreate(Sender: TObject); begin if FileExists(ExtractFilePath(Application.ExeName) + 'webs.txt') then txtWebEspecificas.Lines.LoadFromFile(ExtractFilePath(Application.ExeName) + 'webs.txt'); if FileExists(ExtractFilePath(Application.ExeName) + 'log.txt') then txtLog.Lines.LoadFromFile(ExtractFilePath(Application.ExeName) + 'log.txt'); tTabla.Close; tTabla.DatabaseName := ExtractFilePath(Application.ExeName) + 'datos'; // tTabla.Open; tTablaInsertar.Close; tTablaInsertar.DatabaseName := ExtractFilePath(Application.ExeName) + 'datos'; // tTablaInsertar.Open; tConsulta.Close; tConsulta.DatabaseName := ExtractFilePath(Application.ExeName) + 'datos'; end; procedure TformMenuPrincipal.FormClose(Sender: TObject; var Action: TCloseAction); begin txtWebEspecificas.Lines.SaveToFile(ExtractFilePath(Application.ExeName) + 'webs.txt');; end; procedure TformMenuPrincipal.actCancelarCapturaExecute(Sender: TObject); begin cancelarProceso := true; end; procedure TformMenuPrincipal.actAbrirBDExecute(Sender: TObject); begin tTabla.Open; ttabla.Refresh; end; procedure TformMenuPrincipal.actVisualizarExecute(Sender: TObject); begin if tTabla.RecordCount > 0 then begin tTablaContenido.SaveToFile(ExtractFilePath (Application.ExeName) + tTablaURL.Value + '.html'); ShellExecute(Handle, Nil, PChar(ExtractFilePath (Application.ExeName) + tTablaURL.Value + '.html'), Nil, Nil, SW_SHOWNORMAL); end; end; procedure TformMenuPrincipal.actVisualizarHTMLExecute(Sender: TObject); begin if tTabla.RecordCount > 0 then begin if not varisnull(tTablaContenido.Value) then begin formVisualizacionHTML.mHTML.Text := tTablaContenido.Value; formvisualizacionHTML.show; end; end; end; procedure TformMenuPrincipal.LWEBClick(Sender: TObject); begin ShellExecute(Handle, Nil, PChar(LWEB.CAPTION), Nil, Nil, SW_SHOWNORMAL); end; end. |






{kind=link}