Desplegar un clúster Hadoop con Docker Desktop para big data. Desplegaremos Hadoop en su versión 3.3.6 con Docker Desktop sobre un equipo Windows. El proceso es similar para Docker sobre Linux. Crearemos los NodeName, la red, el ResourceManager, los DataNodes y NodeManagers y probaremos tanto el HDFS como el clúster Hadoop ejecutando una aplicación MapReduce con YARN.
- Qué es Hadoop, HDFS, YARN, MapReduce.
- Requisitos para montar un clúster Hadoop con Docker Desktop.
- Instalación base de Hadoop con Docker Desktop.
- Crear imagen para NodeName para HDFS.
- Crear red virtual en Docker para interconexión de nodos.
- Iniciar un contenedor NodeName para probar acceso web y acceso al shell de comandos.
- Crear imagen para ResourceManager.
- Crear imagen para los DataNodes y NodeManagers.
- Iniciar los tres contenedores que serán los workers en base a la imagen creada anteriormente.
- Probando el HDFS.
- Probando todo el clúster Hadoop ejecutando una aplicación MapReduce con YARN.
- Realizar el despliegue del clúster Hadoop sobre Docker de forma automática con Docker Compose.
Qué es Hadoop, HDFS, YARN, MapReduce
Hadoop
Hadoop es un framework open source para aplicaciones distribuidas que trabajan con Big Data. Hadoop permite el procesamiento de enormes cantidades de datos en grandes clústeres de hardware barato (commodity clusters).
Hadoop tiene las siguientes características:
- Escala: petabytes de datos en miles de nodos.
- Bajo coste: clústeres baratos o en cloud.
- Facilidad de uso.
- Tolerancia a fallos.
Hadoop tiene la siguiente arquitectura:
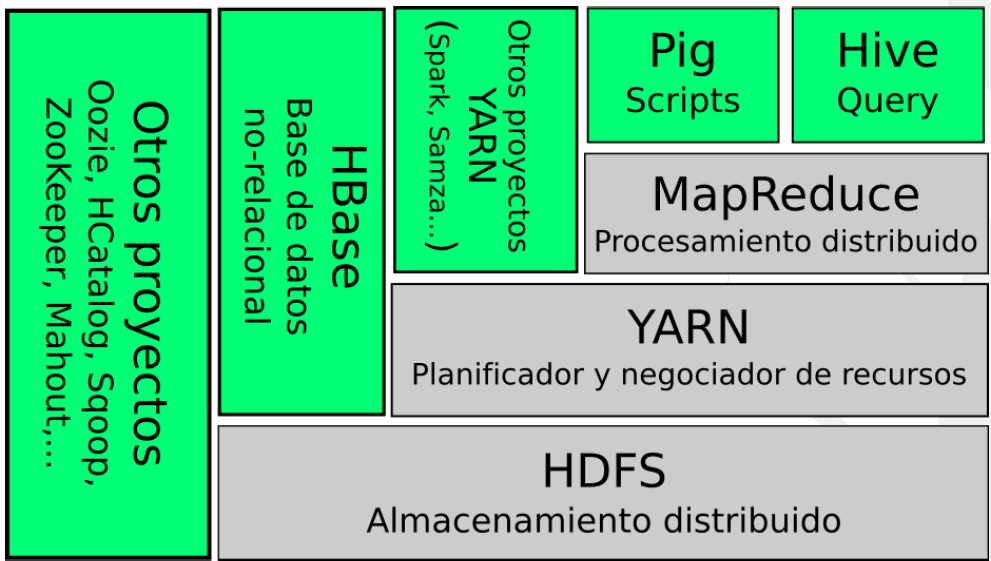
- Almacenamiento distribuido: HDFS (Hadoop Distributed File System).
- Planificación de tareas y negociación de recursos: YARN (Yet Another Resource Negotiator).
- Procesamiento distribuido: MapReduce (librería que permite crear o diseñar aplicaciones).
HDFS
HDFS, como hemos indicado anteriormente, es un sistema de ficheros, que presenta las siguientes ventajas:
- Diseñado para almacenar ficheros muy grandes,.
- Elevado ancho de banda.
- Elevada fiabilidad gracias a la replicación (los ficheros se dividen en bloques que se replican en diferentes nodos del clúster).
HDFS presenta algunas desventajas:
- Elevada latencia.
- Poco eficiente cuando hay muchos ficheros pequeños.
HDFS utiliza varios demonios (servicios) para su funcionamiento:
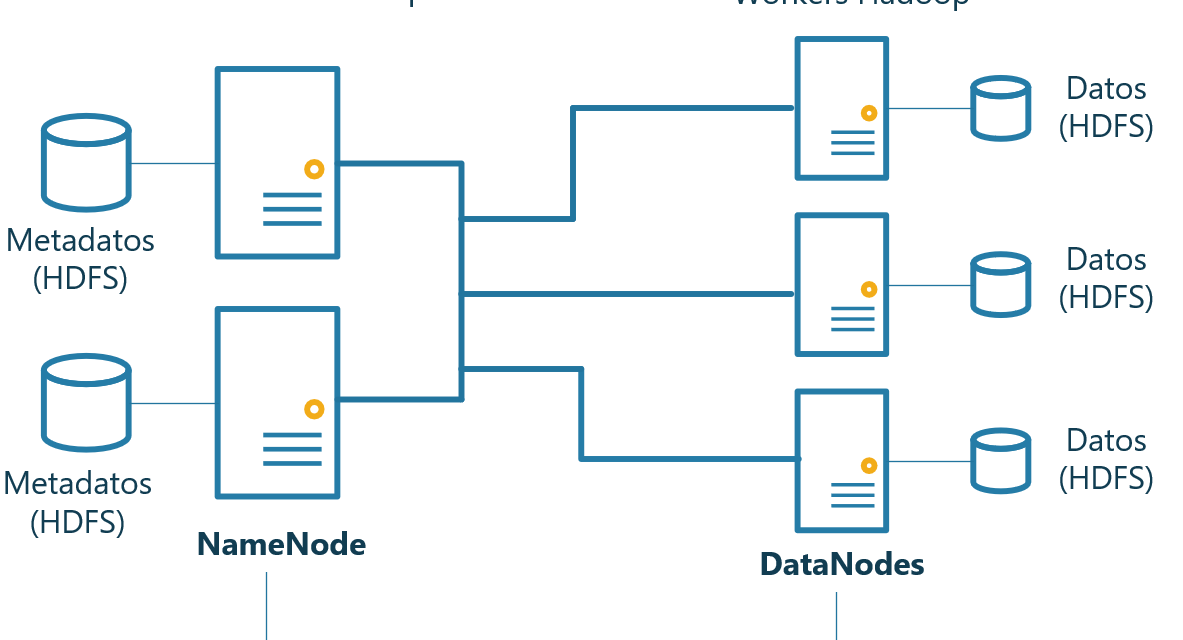
- NameNode: mantiene la información (metadatos) de los ficheros y los bloques en los que residen. No almacena la información en si. El concepto es similar a una tabla de asignación de ficheros (FAT).
- DataNodes: mantiene los bloques de datos. Los DataNodes no saben dónde reside cada bloque de cada fichero, únicamente almacenan la información en si, el que sabe dónde está cada bloque es el NameNode.
El despliegue que se realizará en este artículo será el siguiente:

Teniendo en cuenta que se desplegará únicamente un NameNode y tres DataNodes.
Por defecto, HDFS creará bloques de 128MB de tamaño y cada bloque se replicará, al menos, tres veces (en tres nodos DataNodes diferentes). Estos y otros parámetros son configurables.
HDFS incluye algunos comandos para el manejo de ficheros:
| Comando | Acción |
| hdfs dfs -ls <ruta> | Lista ficheros |
| hdfs dfs -ls -R <ruta> | Lista ficheros recursivamente |
| hdfs dfs -cp <origen> <destino> | Copia ficheros de HDFS a HDFS |
| hdfs dfs -mv <origen> <destino> | Mueve ficheros de HDFS a HDFS |
| hdfs dfs -rm <ruta> | Borra ficheros en HDFS |
| hdfs dfs -rm -r <ruta> | Borra ficheros recursivamente en HDFS |
| hdfs dfs -cat <ruta> | Muestra el contenido del fichero |
| hdfs dfs -tail <ruta> | Muestra el final del fichero |
| hdfs dfs -stat <ruta> | Muestra estadísticas del fichero |
| hdfs dfs -mkdir <ruta> | Crea directorio en HDFS |
| hdfs dfs -chmod <ruta> | Cambia los permisos del fichero |
| hdfs dfs -chown <ruta> | Cambia el propietario del fichero |
| hdfs dfs -put <local> <destino hdfs> | Copia ficheros de local a HDFS |
| hdfs dfs -get <origen hdfs> <destino local> | Copia de HDFS a local |
YARN
YARN, como hemos indicado anteriormente, es el planificador de tareas y el negociador de recursos del clúster Hadoop.
Se encarga de la gestión de recursos y job-scheduling/monitorización, usando tres demonios:
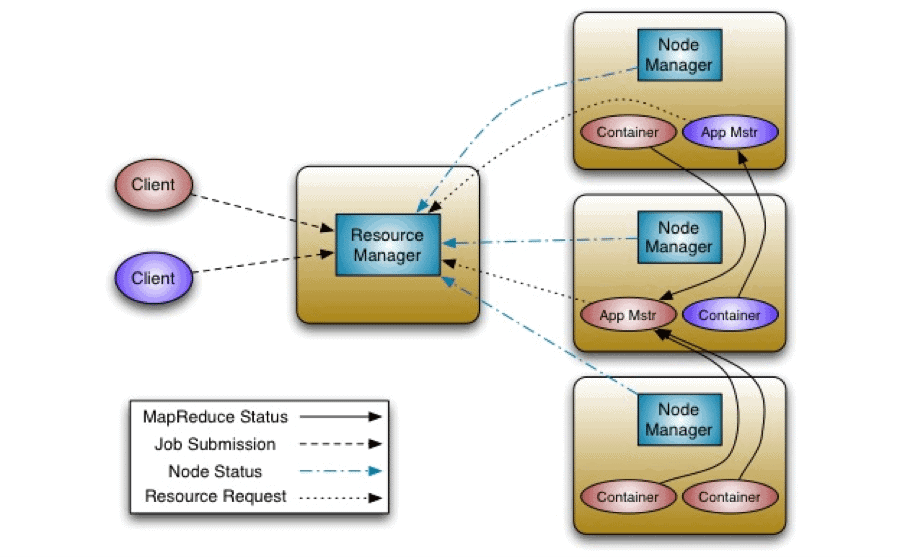
- ResourceManager (RM): planificador general. Arbitra los recursos entre las aplicaciones en el sistema. Es un demonio global y obtiene datos del estado del clúster, de todos los node managers.
- NodeManagers (NM): monitorización de recursos del clúster, uno por nodo.
- ApplicationMasters (AM): gestión de aplicaciones, uno por aplicación. Se encarga de gestionar el ciclo de vida de la aplicación. Solicita recursos (contenedores) al ResourceManager y ejecuta la aplicación en esos contenedores. Trabaja con los Nodemanagers para ejecutar y monitorizar las tareas.
Permite que diferentes tipos de aplicaciones (no solo MapReduce) se ejecuten en el clúster. Las aplicaciones se despliegan en “contenedores”, que son máquinas virtuales de Java (JVMs)
Programación MapReduce
Se trata de un modelo de programación data-parallel diseñado para la escalabilidad y la tolerancia a fallos en grandes sistemas de commodity hardware.
Algunas de sus características:
- Está basado en la combinación de operaciones Map y Reduce.
- Los datos de entrada se organizan como listas de pares clave/valor. Estos datos están distribuidos y replicados en HDFS.
La operación Map:
- Aplica la misma función a diferentes bloques de entrada.
- Operación totalmente paralela: las funciones map se ejecutan sobre los nodos del clúster Hadoop.
- Cada función map lee los datos del nodo en el que se ejecuta.
La operación Reduce:
- Realiza una operación de reducción sobre las salidas de los map.
- Puede haber varios reduces.
Requisitos para montar un clúster Hadoop con Docker Desktop
Necesitaremos disponer de un equipo con Docker Desktop (sea en Windows o en Linux). En el siguiente artículo explicamos cómo desplegar Docker Desktop sobre un equipo Windows:
Y en este otro desplegamos Docker Desktop en Linux:
El equipo anfitrión con Docker Desktop debe tener conexión a Internet.
Por supuesto, en un despliegue de producción real, crearemos los nodos en equipos físicos diferentes con discos duros diferentes, para que el clúster tenga sentido, por si cae algún nodo, el resto seguirán prestando el servicio. En este artículo, a modo de ejemplo, montamos los nodos en un mismo equipo anfitrión, si el equipo cae, caerán todos los nodos.
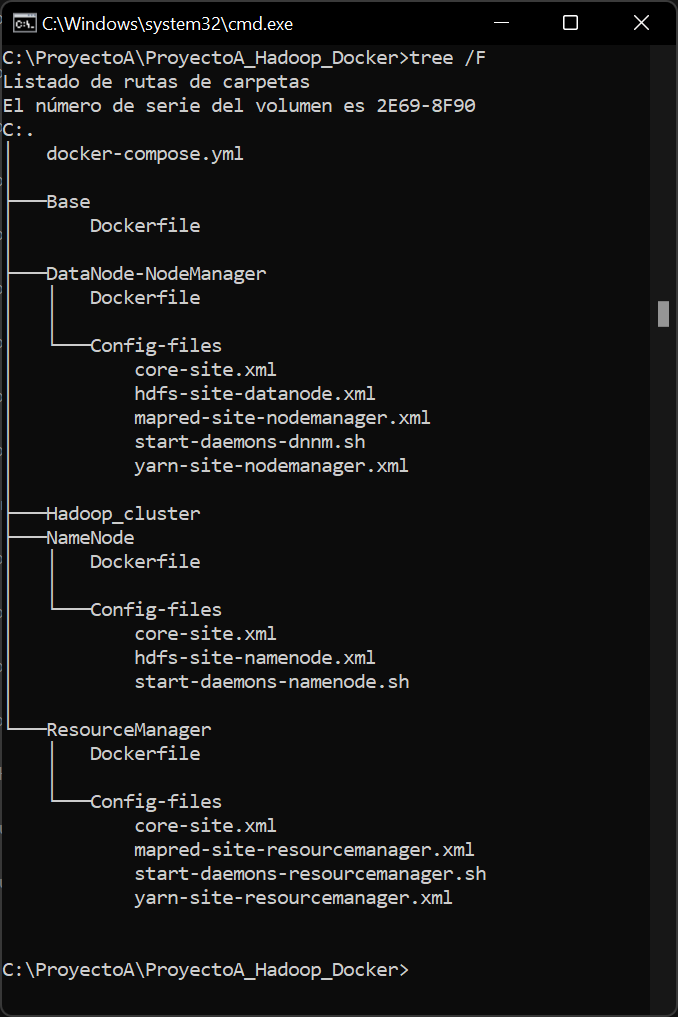
Para el despliegue del clúster Hadoop sobre Docker, necesitaremos una serie de carpetas y ficheros de configuración, que podemos descargar desde:
Descargaremos el fichero anterior y lo descomprimiremos en una carpeta de nuestro equipo anfitrión con Docker Desktop. Este fichero descomprimido contendrá las siguientes carpetas y ficheros, necesarios para el despliegue:
Instalación base de Hadoop con Docker Desktop
Iniciaremos el despliegue del clúster construyendo una imagen Hadoop base (con Linux Ubuntu). Para ello, desde la línea de comandos, accederemos a la carpeta donde tengamos los ficheros de despliegue del clúster (que podéis descargar desde este enlace). Una vez en la carpeta de los ficheros de despliegue, accederemos a la carpeta Base:
|
1 |
cd Base |
Y ejecutaremos el siguiente comando:
|
1 |
docker build -t hadoop-base-image . |
Con el comando anterior, indicamos a Docker Desktop que use el fichero dockerfile de la carpeta actual.
Se iniciará, de forma automática, la descarga y despliegue de una imagen con el sistema operativo Linux Ubuntu:
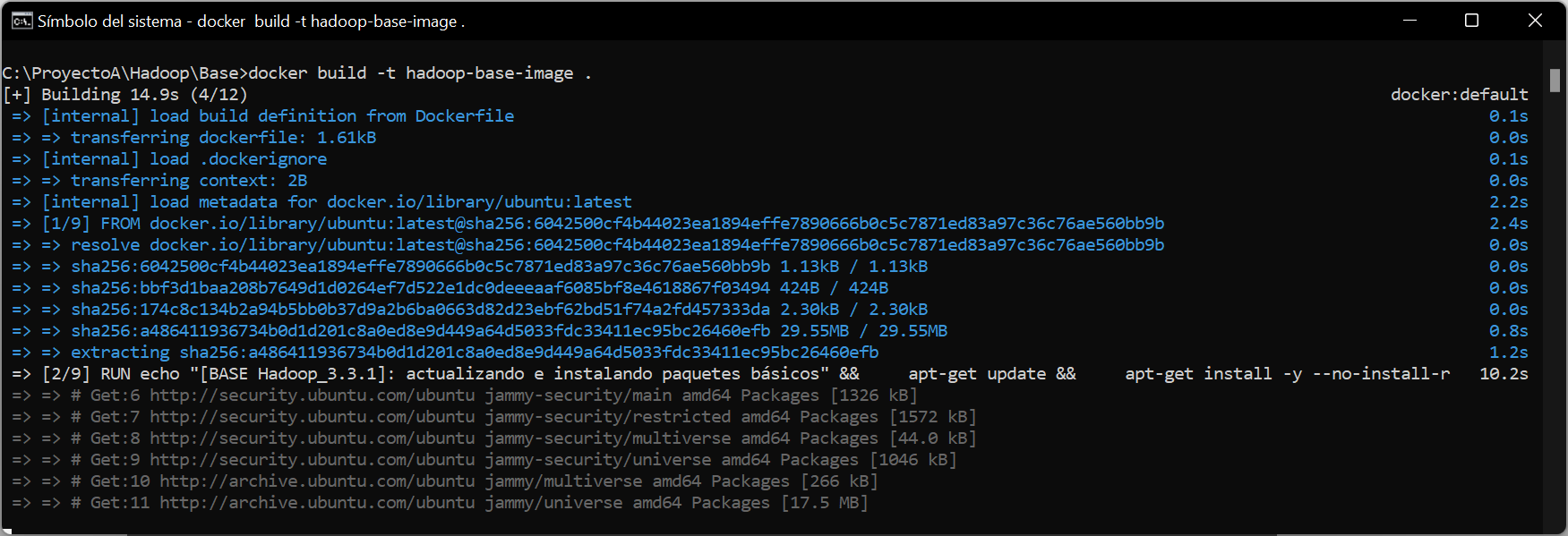
Comprobaremos que la imagen se ha desplegado correctamente, ejecutando el comando:
|
1 |
docker image ls |
Nos mostrará la imagen desplegada, con el nombre «hadoop-base-image»:

Crear imagen docker NodeName para HDFS
Crearemos una imagen base para el NodeName, que será el que mantenga la información (metadatos) de los ficheros y bloques que residen en el HDFS (como hemos indicado anteriormente).
Para crear el NodeName con Linux Ubuntu, accederemos a la carpeta NodeName de los ficheros de despliegue y ejecutaremos el comando:
|
1 |
docker build -t namenode-image . |
Crear red virtual en Docker para interconexión de nodos
Necesitaremos una red virtual en Docker para la interconexión de todos los nodos del clúster. Para crear la red, desde la línea de comandos, ejecutaremos el comando:
|
1 |
docker network create hadoop-net |

Para mostrar la red creada, ejecutaremos el comando:
|
1 |
docker network inspect hadoop-net |
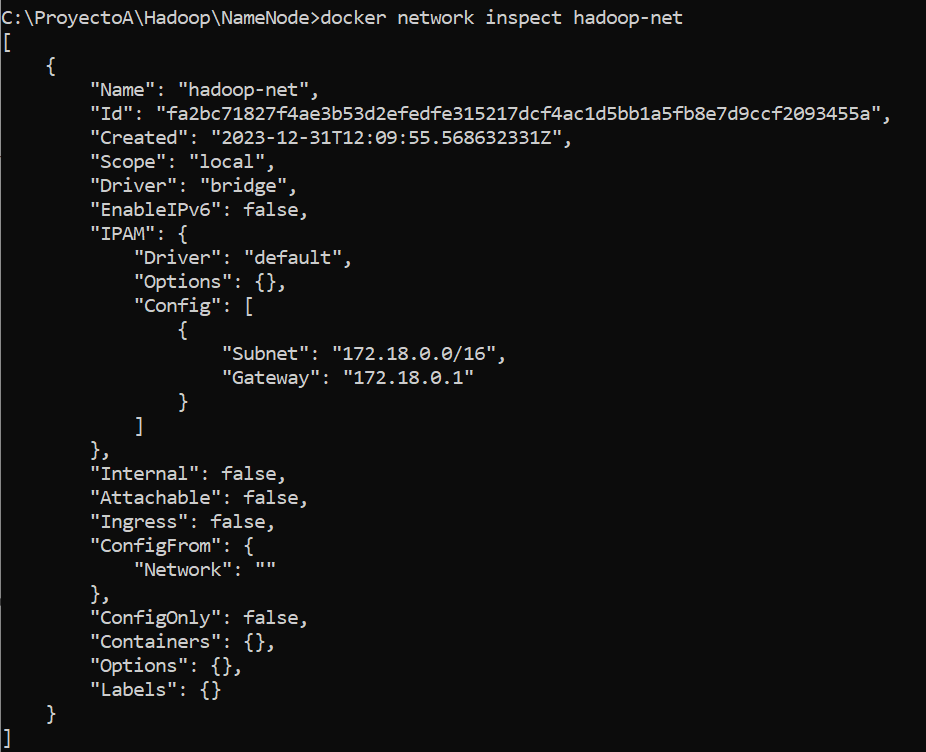
Iniciar un contenedor NodeName para probar acceso web y acceso al shell de comandos
Para iniciar el contenedor NodeName, ejecutaremos el siguiente comando:
|
1 |
docker container run --rm --init --detach --name namenode --network=hadoop-net --hostname namenode -p 9870:9870 namenode-image |
En el caso de Windows, puede que nos solicite acceso el cortafuegos al puerto 9870, de ser así, permitiremos el acceso.
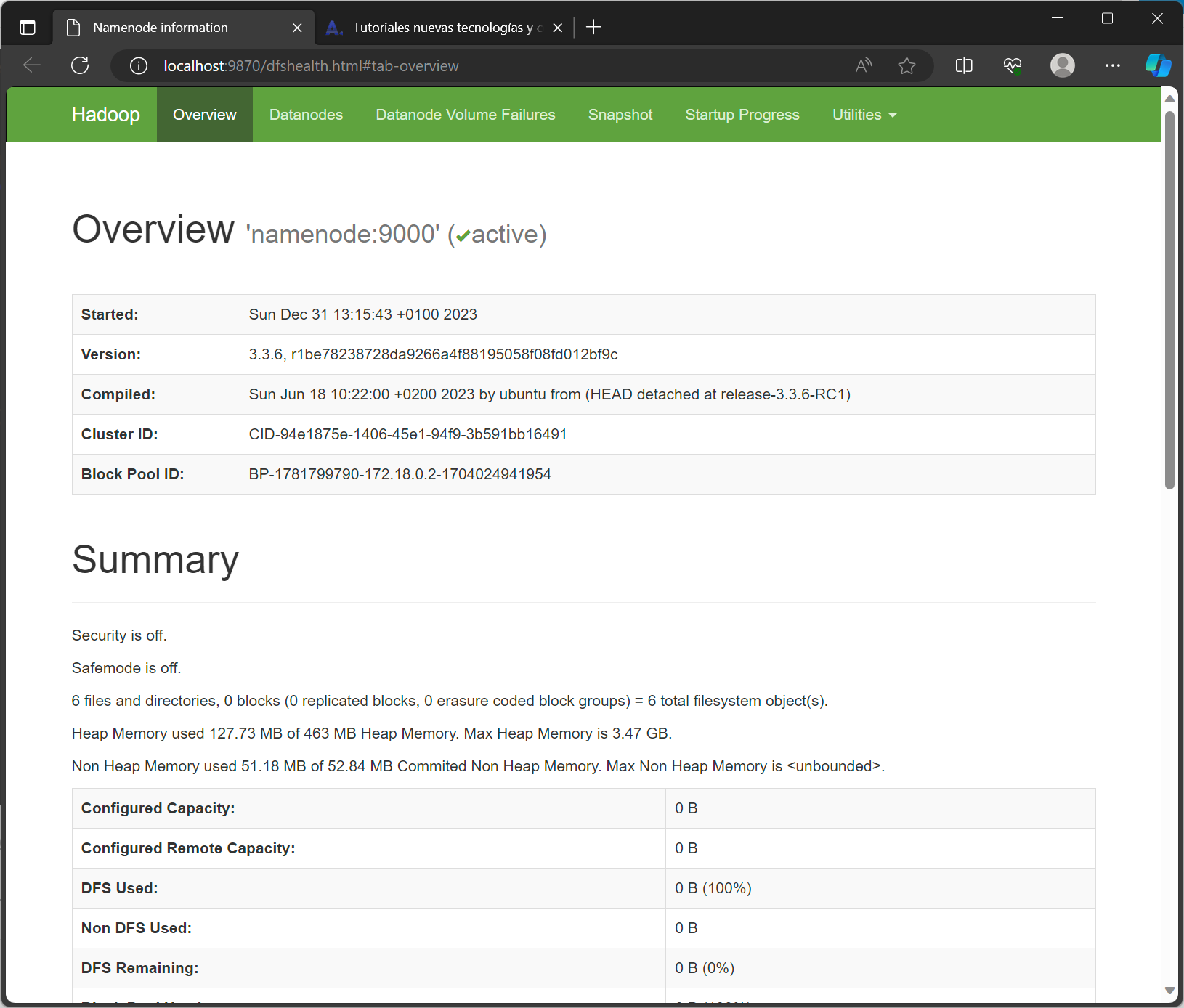
Una vez iniciado el contenedor, podremos acceder al servicio web, abriendo un navegador en el equipo Windows anfitrión de Docker y accediendo a la URL:
http://localhost:9870
Nos mostrará todos los datos del nodo:
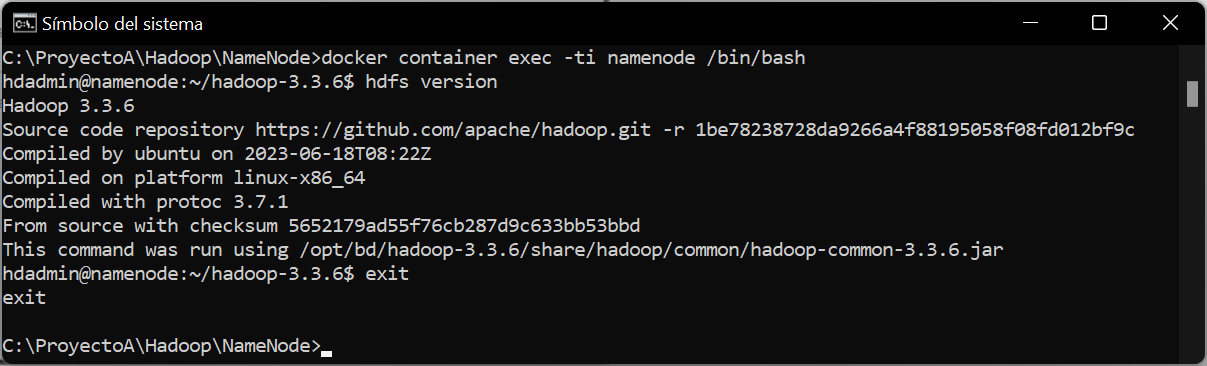
También podremos acceder al propio shell de comandos del nodo, ejecutando desde la línea de comandos del anfitrión de Docker (equipo Windows), el comando:
|
1 |
docker container exec -ti namenode /bin/bash |
Entraremos el el shell de Linux Ubuntu del nodo, desde aquí podremos ejecutar comandos para este nodo, por ejemplo, para mostrar la versión de HDFS, ejecutaremos el comando:
|
1 |
hdfs version |
Para salir del shell del nodo Linux al shell de Windows (anfitrión), ejecutaremos el comando:
|
1 |
exit |
Crear imagen para ResourceManager para YARN
Para crear el contenedor dokcer para el ResourceManager, accederemos a la carpeta ResourceManager y ejecutaremos el comando:
|
1 |
docker build -t resourcemanager-image . |

Ejecutando el siguiente comando nos listará los contenedores desplegados:
|
1 |
docker image ls |

Para iniciar el contenedor ResourceManager creado anteriormente, ejecutaremos el comando:
|
1 |
docker container run --rm --init --detach --name resourcemanager --network=hadoop-net --hostname resourcemanager -p 8088:8088 resourcemanager-image |
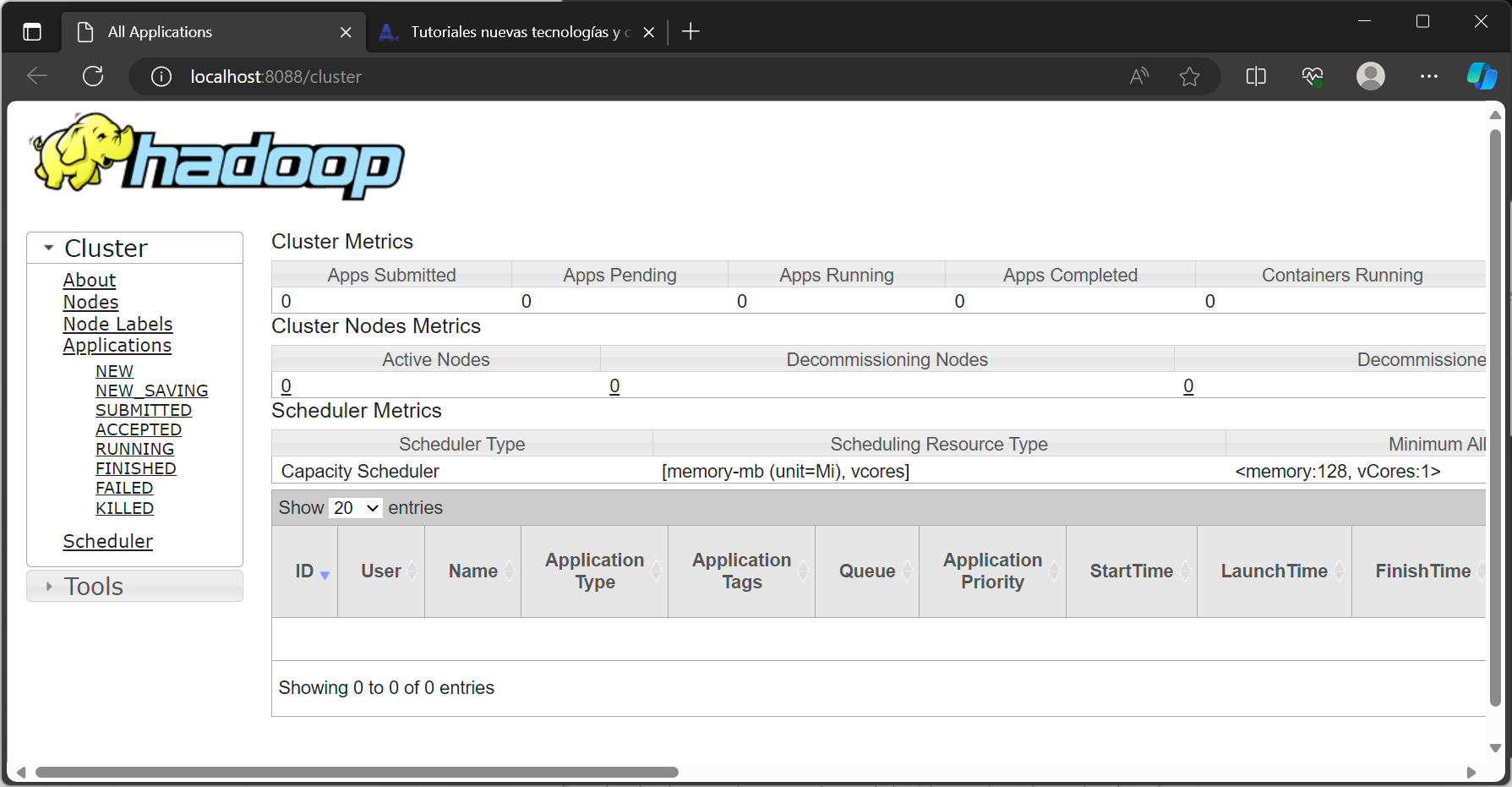
Una vez iniciado, podremos acceder a su web de gestión, desde el navegador del equipo WIndows anfitrión, introduciendo la URL:
http://localhost:8088
Crear imagen para los DataNodes y NodeManagers
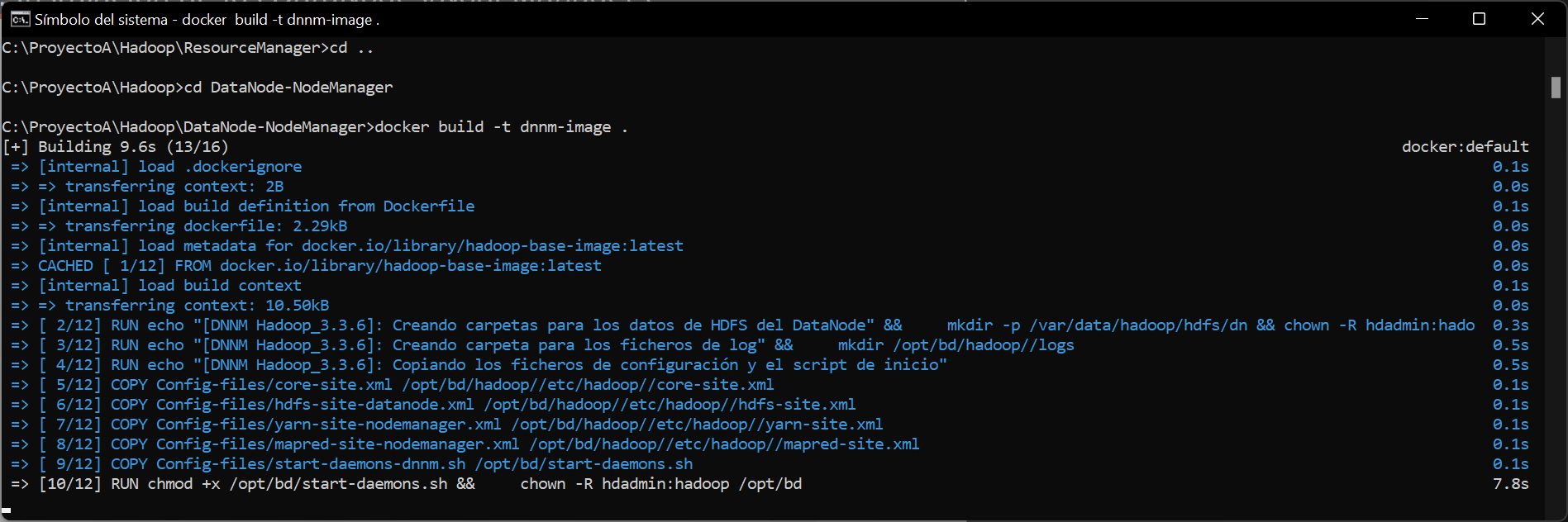
Crearemos la imagen para los DataNodes y los NodeManagers. Para ello, accederemos a la carpeta DataNode-NodeManager de los ficheros del despliegue, y ejecutaremos el comando:
|
1 |
docker build -t dnnm-image . |
Como siempre, podremos comprobar que la imagen está creada correctamente con el comando:
|
1 |
docker image ls |

Iniciar los tres contenedores que serán los workers en base a la imagen creada anteriormente
Una vez creadas todas las imágenes (NodeName, ResourceManager y Datanodes/NodeManagers), iniciaremos tres contenedores que serán tres equipos virtuales correspondientes a los workers, con el nombre dnnm1, dnnm2 y dnnm3. Para ello, ejecutaremos los siguientes comandos:
|
1 2 3 |
docker container run --rm --init --detach --name dnnm1 --network=hadoop-net --hostname dnnm1 dnnm-image docker container run --rm --init --detach --name dnnm2 --network=hadoop-net --hostname dnnm2 dnnm-image docker container run --rm --init --detach --name dnnm3 --network=hadoop-net --hostname dnnm3 dnnm-image |
Todos estos contenedores usarán la red creada anteriormente y usarán como imagen base dnnm-image, creada en el punto anterior.

Si accedemos ahora al servicio web del NodeName veremos que ya se han registrado los tres nodos:

También podremos verlo en el servicio web del ResourceManager:

Probando el HDFS
Probaremos el HDFS copiando algún fichero desde el equipo Linux contenedor al sistema HDFS del Hadoop. Para ello, accederemos al shell del NodeName, ejecutando el comando:
|
1 |
docker container exec -ti namenode /bin/bash |
En el shell de Linux, creamos un fichero llamado fich250M con un tamaño de 250MB, ejecutando el comando:
|
1 |
dd if=/dev/urandom of=fich250M bs=1M count=250 |
Copiaremos el fichero creado al entorno HDFS, a la carpeta /user/hdadmin y lo eliminaremos del equipo Linux, con el comando:
|
1 |
hdfs dfs -put fich250M /user/hdadmin; rm fich250M |
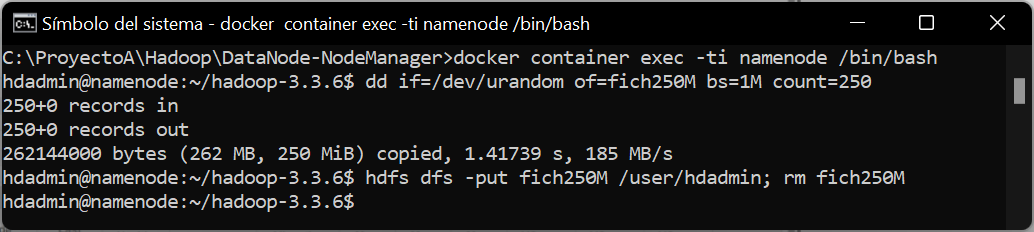
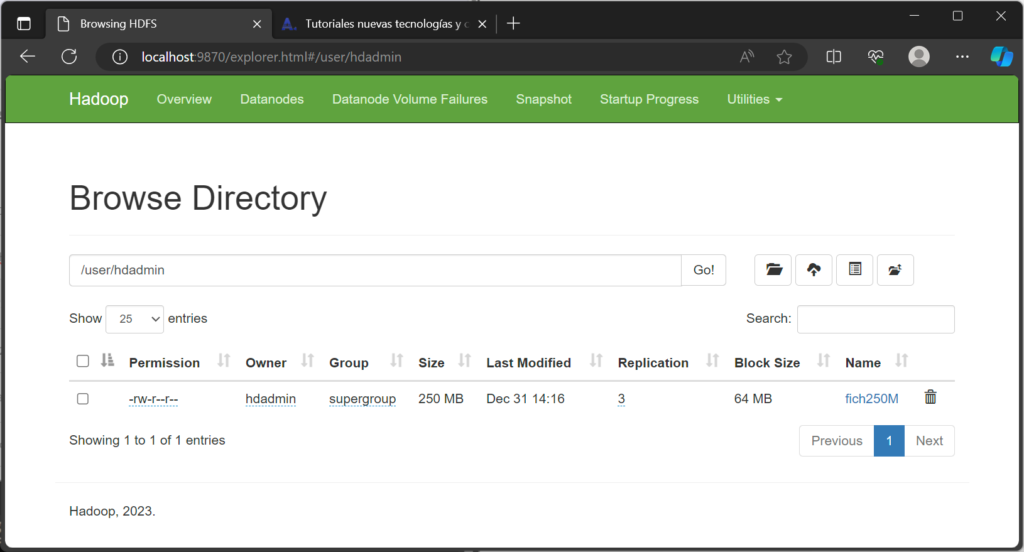
Desde la interfaz web del NodeName, accediendo a «Utilities» – «Browse the filesystem» y explorando la carpeta /user/hdadmin, podremos comprobar que el fichero ha sido subido al entorno HDFS y, además, replicado a los nodos que componen el clúster Hadoop correctamente:
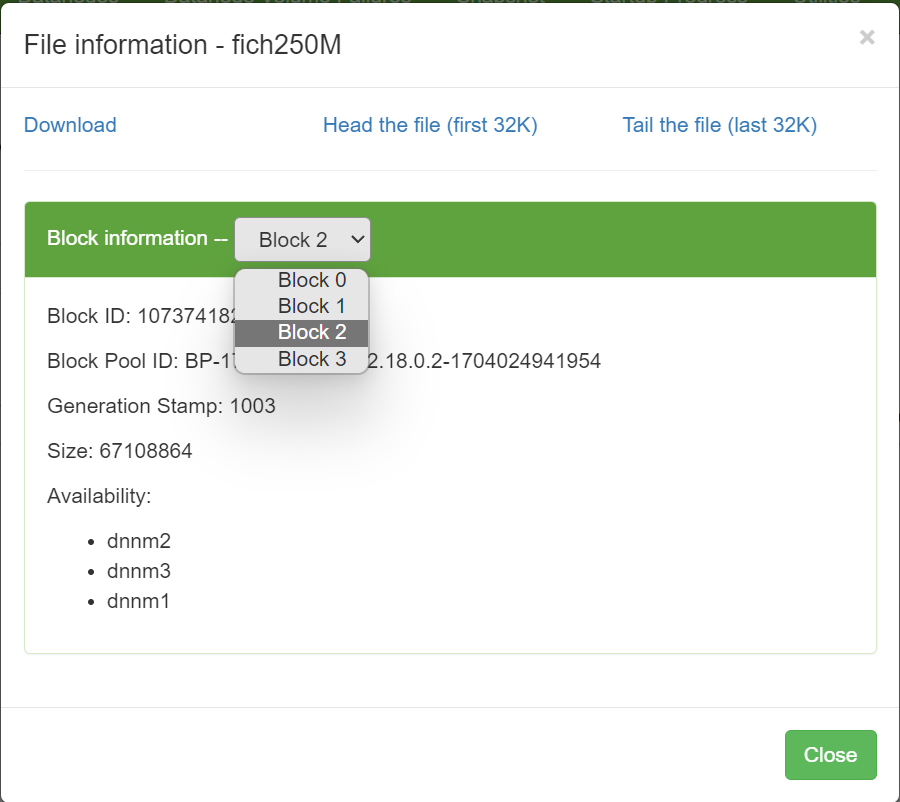
Pulsando en el fichero, podremos ver el número de bloques en los que se ha dividido el fichero y en qué nodo reside cada bloque:
Probando todo el clúster Hadoop ejecutando una aplicación MapReduce con YARN
Por último, para hacer más pruebas del correcto funcionamiento del clúster Hadoop, ejecutaremos una aplicación de ejemplo MapReduce. Para ello, accederemos al shell del ResourceManager, ejecutando el siguiente comando en el terminal del equipo Windows anfitrión de Docker:
|
1 |
docker container exec -ti resourcemanager /bin/bash |
Desde la línea de comandos del Linux que contiene el ResourceManager, ejecutaremos los siguientes comandos para ejecutar una aplicación MR de ejemplo (aproxima el valor de pi):
|
1 2 |
export MR_EXAMPLES=$HADOOP_HOME/share/hadoop/mapreduce yarn jar $MR_EXAMPLES/hadoop-mapreduce-examples-*.jar pi 16 1000 |
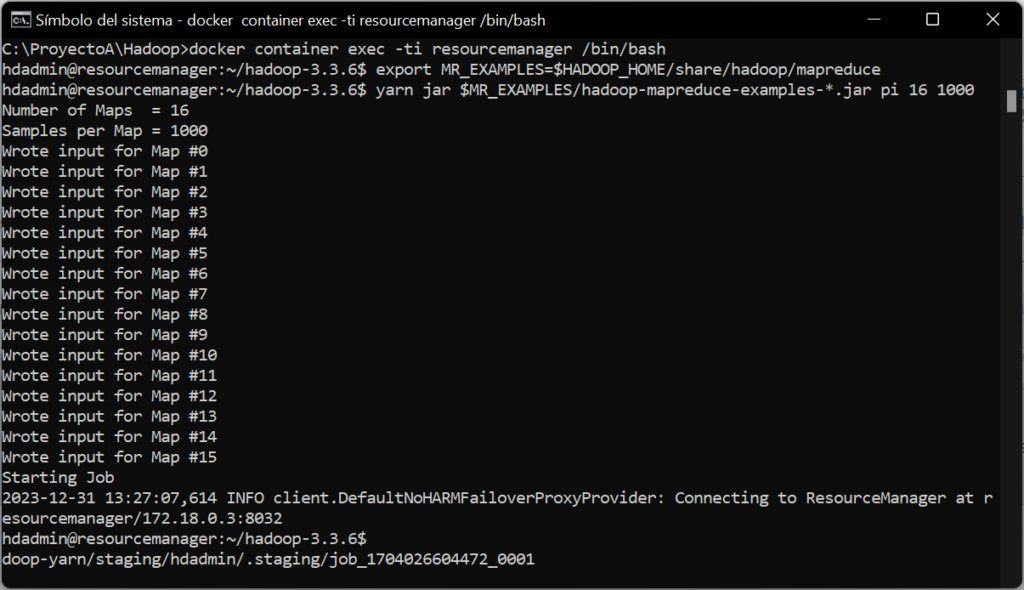
Comprobaremos, en la interfaz web del ResourceManager que, efectivamente, el trabajo se ha ejecutado y ha finalizado correctamente. También doremos comprobar qué nodo del clúster la ejecutó, en nuestro caso en el dnnm1:
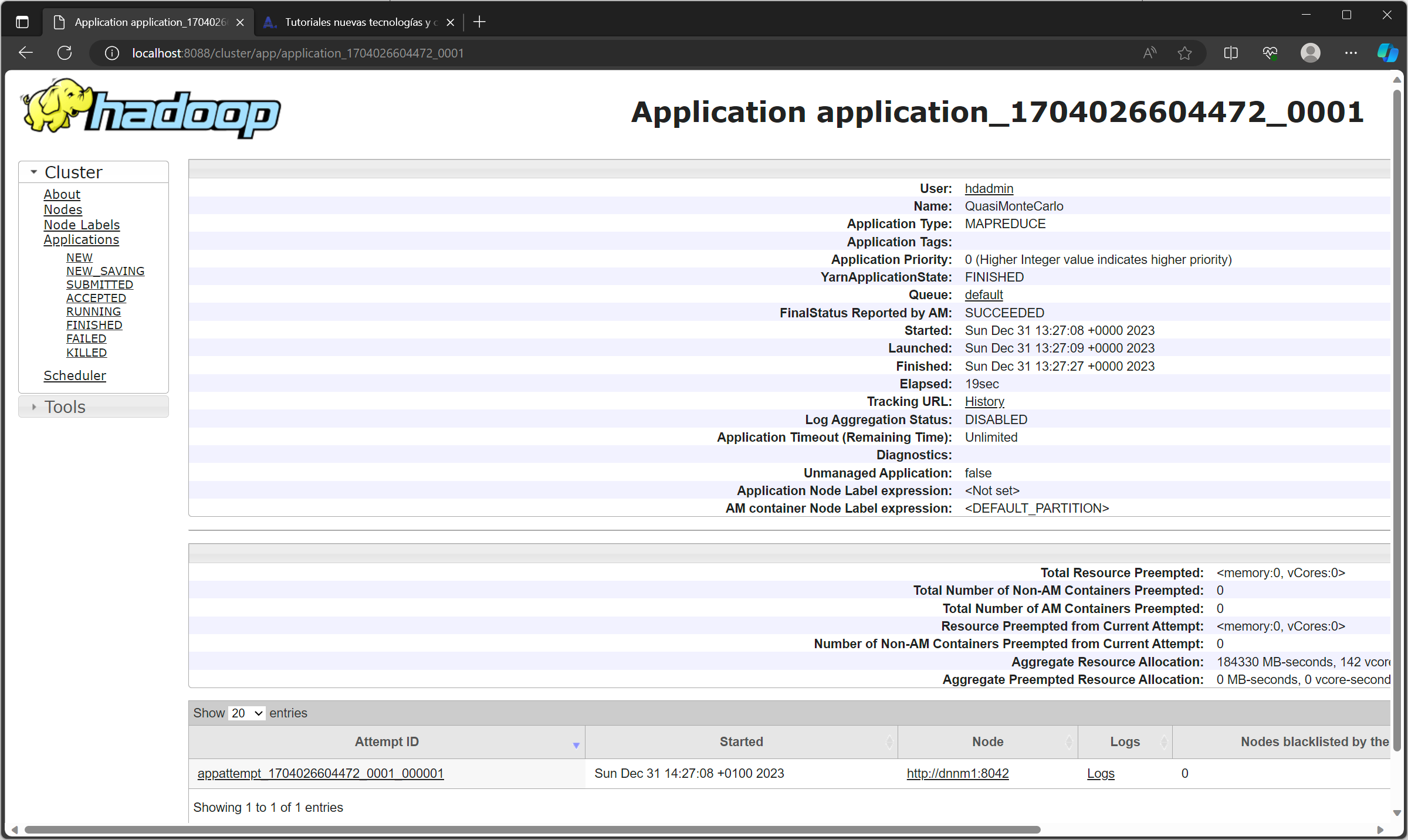
Y el número de contenedores MR que se ejecutaron (en nuestro caso 18):

Realizar el despliegue del clúster Hadoop sobre Docker de forma automática con Docker Compose
En la descarga de los ficheros del despliegue (disponible en este enlace), tendremos disponible el fichero docker-compose.yml, que será el que necesitemos para realizar el despliegue automático de toda la infraestructura anterior, teniendo en cuenta que sí necesitaremos tener creadas las imágenes base.
Si hemos seguido los pasos anteriores y tenemos iniciados los contenedores, antes de hacer el despliegue automático, los detendremos. Para ello, ejecutaremos estos comandos:
|
1 2 |
docker container stop dnnm1 dnnm2 dnnm3 docker container stop namenode resourcemanager |
Para realizar el despliegue automático, con las imágnes base creadas (dnnm1, dnnm2, dnnm3, namenode y resourcemanager) abriremos un shell de comandos en el equipo Windows anfitrión y accederemos a la carpeta de la descarga de los ficheros del despliegue, donde tengamos el fichero docker-compose.yml. Ejecutaremos el siguiente comando para desplegar el clúster Hadoop con tres nodos:
|
1 |
docker compose up --scale dnnm=3 -d |

Para detener el clúster, ejecutaremos el comando:
|
1 |
docker compose stop |
Para iniciarlo, ejecutaremos:
|
1 |
docker compose start |
Y si queremos eliminarlo, ejecutaremos:
|
1 |
docker compose down |






{kind=link}