Preparar datos de entrada en formato CSV y log de accesos web con R. Funciones y ejemplos para filtrar datos, obtener estadísticas y otros valores útiles para el tratamiento de ficheros de accesos web (habitualmente generados por servidores web Apache, Nginx, Tomcat, IIS). Mostramos ejemplos para filtrar resultados, agrupar, sumar, media, mediana, desarrollamos una función con un bucle para obtener datos geográficos de una IP (región, país, ciudad), utilizamos JSON en R, etc.
- Requisitos para tratamiento de ficheros de logs de accesos web con R.
- Instalar librerías necesarias para el proyecto R y configuración inicial de los datos leídos.
- Análisis de la información, filtros, sumatorios, búsquedas, funciones, geolocalización de IP en R.
- Descarga del código R completo y fichero de log de ejemplo.
Requisitos para tratamiento de ficheros de logs de accesos web con R
El requisito único será disponer de R y RStudio, así como de sus librerías básicas. En el siguiente artículo explicamos cómo instalar R, RStudio y sus librerías básicas:
Dispondremos de uno o varios ficheros de log de accesos web, generados habitualmente por servidores web como Apache, Nginx, Tomcat, IIS, etc. Con el formato:
|
1 2 3 4 5 6 7 |
103.143.1.171 [19:13:53:15] "GET /Software.html HTTP/1.0" 100 1497 query1.proyec.cs.cmu.com [19:13:53:36] "GET /contabilidad.html HTTP/1.0" 100 1315 tanuki.proyectoa.com [19:13:53:53] "GET /facturacon.html HTTP/1.0" 100 1014 wpbfl1-45.ajpd.net [19:13:54:15] "GET / HTTP/1.0" 100 4889 wpbfl1-45.ajpd.net [19:13:54:16] "GET /icons/logo_small.gif HTTP/1.0" 100 1614 wpbfl1-45.ajpd.net [19:13:54:18] "GET /logos/small.gif HTTP/1.0" 100 935 140.111.68.165 [19:13:54:19] "GET /logos/us.gif HTTP/1.0" 100 1788 |
Descargaremos estos ficheros de log en la carpeta donde crearemos el proyecto R. Desde RStudio, estableceremos esta carpeta como la carpeta de trabajo, para no tener que indicar las rutas en el código R. En nuestro caso trabajaremos con el fichero log_http.csv (disponible en la descarga del código fuente R del ejemplo completo).

Instalar librerías necesarias para el proyecto R y configuración inicial de los datos leídos
Abriremos RStudio, asignaremos el directorio de trabajo (como hemos indicado anteriormente) e instalaremos las siguientes librerías R: readr, jsonlite, tzdb. Con los comandos:
|
1 2 3 |
install.packages("readr") install.packages("jsonlite") install.packages("tzdb") |
Las usaremos con los comandos:
|
1 2 |
library(jsonlite); library(readr); |
Realizaremos una primera lectura del fichero de log log_http.csv, que guardaremos en una variable y mostraremos en R, con el código R:
|
1 2 |
dsLog <- read_table("log_http.csv", col_names = FALSE); View(dsLog); |
RStudio leerá los valores del fichero de log y los mostrará en forma de tabla. Dará algunos warning que son normales, por el tipo de datos y valores nulos:

A continuación ejecutaremos el siguiente comando para obtener un resumen preliminar de los datos leídos:
|
1 |
summary(dsLog); |
Nos mostrará todas las columnas del dataset, el nombre que le ha asignado de forma automática, el tipo de datos y el tamaño:

Comprobamos el número de columnas, número de filas, primeros registros (elementos) y tipo de datos de cada fila con:
|
1 2 3 4 |
nrow(dsLog); ncol(dsLog); head(dsLog); sapply(dsLog, class); |

Para mostrar solo el nombre de las columnas del dataset:
|
1 |
colnames(dsLog); |
Podremos cambiar el nombre de las columnas con el siguiente código, dejando las columnas ip, fecha, tipo, url, protocolo, codigo_retorno y tamano_respuesta:
|
1 2 |
column_names <- c("ip","fecha","tipo","url","protocolo","codigo_retorno","tamano_respuesta"); colnames(dsLog) <- column_names; |
A continuación formatearemos los campos (columnas) si fuera necesario, sobre todo para establecer el tipo de datos correcto para su manipulación. A continuación mostramos el código R para:
- ip: estableceremos este campo a factor.
- protocolo: estableceremos este campo a factor.
- codigo_retorno: estableceremos este campo a factor.
- tamano_respuesta: estableceremos este campo a numérico. En este caso dará algunos warning: NAs introduced by coercion, debido a que habrá valores nulos, los ignoraremos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#Establecemos el campo ip como factor dsLog$ip <- as.factor(dsLog$ip); #Mostramos los factores levels(dsLog$ip); #Establecemos el campo protocolo como factor dsLog$protocolo <- as.factor(dsLog$protocolo); #Mostramos los factores levels(dsLog$protocolo); #Revisamos el campo fecha y recurso por si necesitamos modificar el tipo, en este caso no #Establecemos el campo codigo_retorno como factor dsLog$codigo_retorno <- as.factor(dsLog$codigo_retorno); levels(dsLog$codigo_retorno); #Establecemos el campo tamano_respuesta como numérico dsLog$tamano_respuesta <- as.numeric(dsLog$tamano_respuesta); #Volvemos a mostrar el sumario tras las modificaciones summary(dsLog); |
Al volver a hacer un summary, nos mostrará los nuevos nombres de columnas, los nuevos tipos de datos e incluso en la columna numérica (tamano_respuesta) nos calculará el mínimo, el máximo, la media, la mediana (media de las dos posiciones centrales), el primer cuartil (mediana de la primera mitad de los valores) y el número de campos con nulo. Para los campos de tipo factor nos mostrará agrupados los valores y el número de apariciones (de los primeros).

Continuamos formateando y revisando columnas y valores, para optimizar al máximo los resultados de la manipulación posterior. Por ejemplo, reemplazar los valores NA (nulos) de la columna tamano_respuesta por 0. En primer lugar mostraremos todos los valores del campo «tamano_respuesta», con:
|
1 |
dsLog$tamano_respuesta; |
Para mostrar sólo un valor concreto de un campo en una posición usaremos:
|
1 2 |
dsLog$tamano_respuesta[1]; dsLog$tamano_respuesta[11]; |
En los ejemplos anteriores se mostrará el valor del campo «tamano_respuesta» en la posición 1 y en la posición 11, que nos devolverá para nuestro dataset:
1497
NA
Para convertir los valores NA del campo tamano_respuesta a 0, usaremos:
|
1 |
dsLog$tamano_respuesta[is.na(dsLog$tamano_respuesta)] <- 0; |
Análisis de la información, filtros, sumatorios, búsquedas, funciones, geolocalización de IP en R
Una vez configurada la información a tratar (nombres de columnas, tipos de datos, nulos, etc.) iniciaremos el tratamiento propiamente dicho. A continuación mostramos el código fuente en R, comentado, indicando las operaciones realizadas para obtener sumatorios, filtros, agrupaciones, etc. Indicaremos la pregunta (el ejercicio de ejemplo) y su solución.
Empezamos con la suma de todos los valores del campo «tamano_respuesta» y de la media, también mostramos cómo evitar los nulos (NA), si los hubiera:
|
1 2 3 4 5 6 7 8 |
#Suma de todos los valores del campo tamano_respuesta sum(dsLog$tamano_respuesta); #Si tuviéramos NA (nulos) y queremos evitarlos podemos usar sum(dsLog$tamano_respuesta, na.rm = TRUE); #Media de todos los valores del campo tamano_respuesta mean(as.numeric(dsLog$tamano_respuesta)); #Al igual que para la suma, si queremos evitar los nulos mean(as.numeric(dsLog$tamano_respuesta), na.rm = TRUE); |

¿Cuál es la IP/Dominio origen con mayor número de peticiones de código de retorno 200?
|
1 2 3 4 5 6 7 8 9 |
## ¿Cuál es la IP origen con mayor número de peticiones de código de retorno 100? ## #Para resolver esta pregunta, en primer lugar filtramos por codigo_retorno=100 y guardamos en dataset dsPeticiones100 <- dsLog[dsLog$codigo_retorno == "100", c("ip", "codigo_retorno")]; #Convertimos el dataset a table dsPeticiones100tb <- table(dsPeticiones100$ip); #Aplicamos la agrupación y filtro para mostrar la IP con más peticiones resultadoIPPeticiones100 <- dsPeticiones100tb[head(order(dsPeticiones100tb,decreasing = TRUE), n = 1)]; #Mostramos el resultado resultadoIPPeticiones100; |
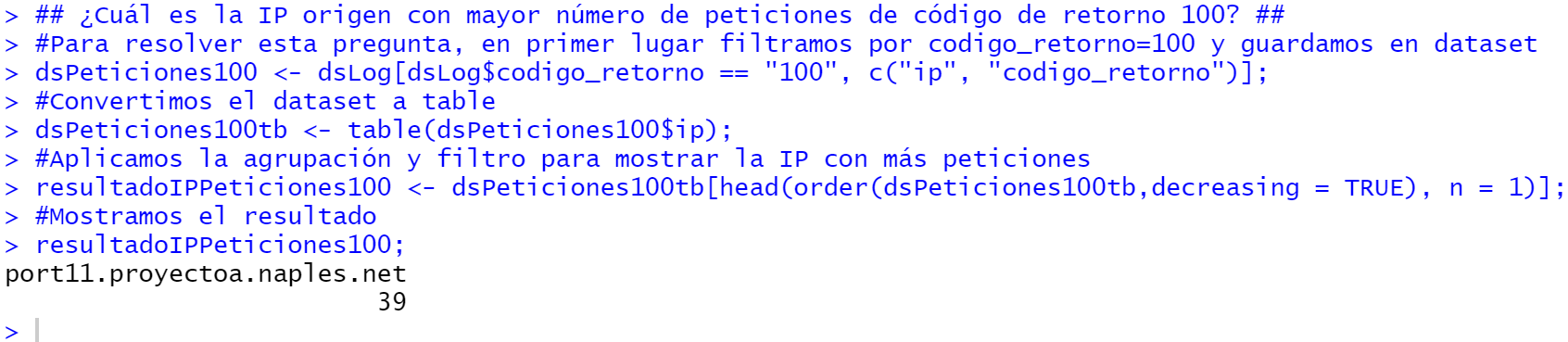
¿Cuál es el número total de IP/Dominios únicas (no repetidas)?
|
1 2 3 4 5 |
## ¿Cuál es el número total de IP únicas (no repetidas)? ## #En primer lugar, aunque no es necesario, obtenemos las IP únicas unique(dsLog$ip); #Contamos las IP únicas length(unique(dsLog$ip)); |
¿Cuál es la frecuencia de aparición de cada IP/Dominio del dsLog completo?
|
1 2 3 4 5 6 7 |
## ¿Cuál es la frecuencia de aparición de cada IP/URL del dsLog completo? ## #Convertimos a table el campo IP tbFrecuencia <- table(dsLog$ip); #Aplicamos agrupación a la tabla tbFrecuencia, decreciente, para mostrar las de mayor frecuencia primero tbFrecuencia <- tbFrecuencia[order(tbFrecuencia, decreasing = TRUE)]; #Mostramos los resultados head(tbFrecuencia); |
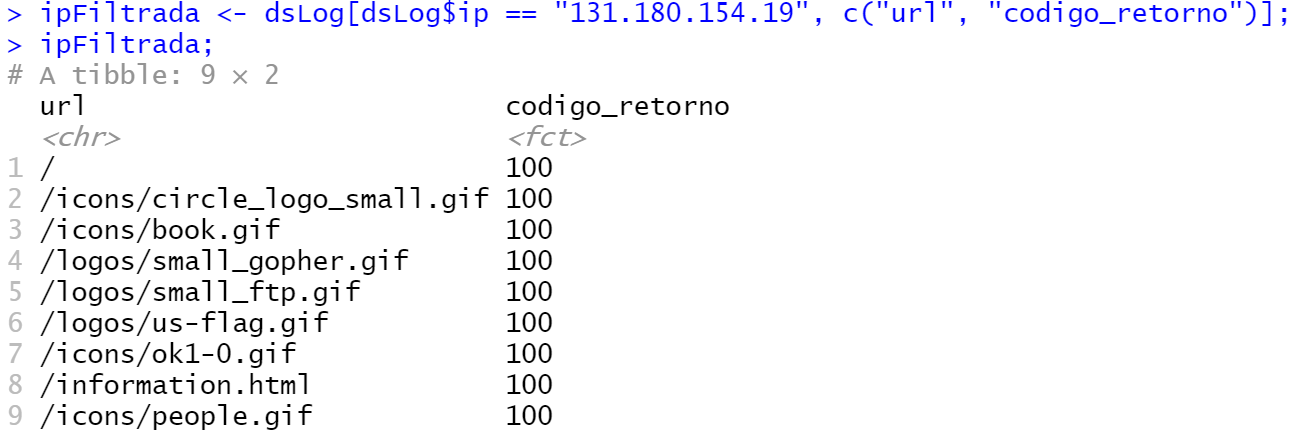
Ejercicio para filtrar información. Dada una IP/Dominio, mostrar la URL y el código de retorno:
|
1 2 3 |
## Ejercicio para filtrar información. Dada una IP, mostrar la URL y el código de retorno ipFiltrada <- dsLog[dsLog$ip == "131.180.154.19", c("url", "codigo_retorno")]; ipFiltrada; |
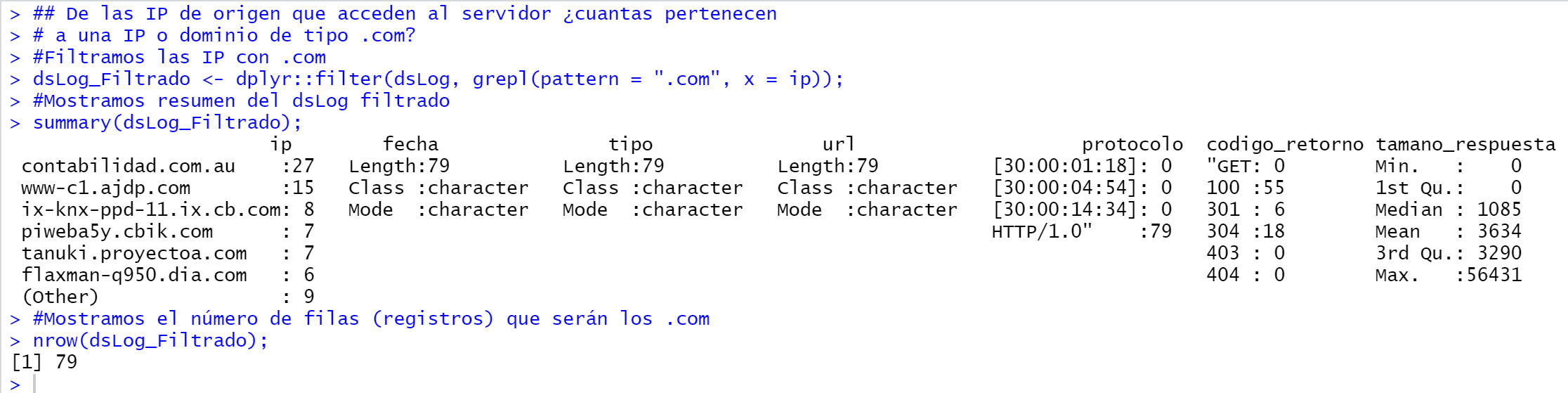
De las IP/Dominios de origen que acceden al servidor ¿cuántas pertenecen a un dominio de tipo .com?
|
1 2 3 4 5 6 7 8 |
## De las IP de origen que acceden al servidor ¿cuántas pertenecen # a un dominio de tipo .com? #Filtramos las IP con .com dsLog_Filtrado <- dplyr::filter(dsLog, grepl(pattern = ".com", x = ip)); #Mostramos resumen del dsLog filtrado summary(dsLog_Filtrado); #Mostramos el número de filas (registros) que serán los .com nrow(dsLog_Filtrado); |
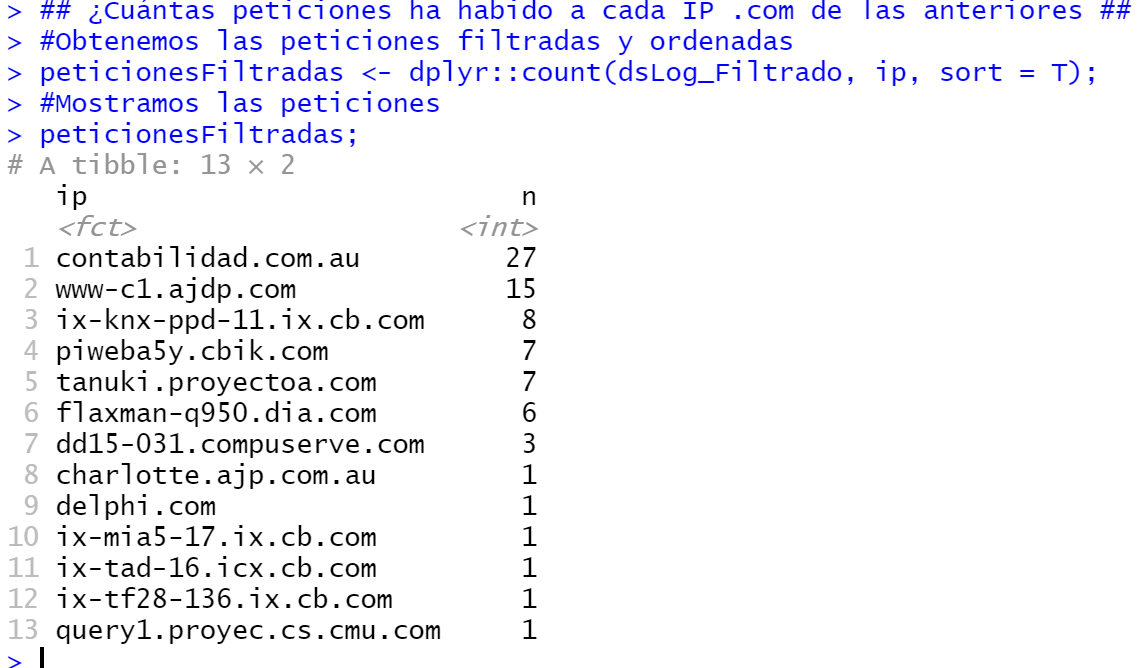
¿Cuántas peticiones ha habido a cada IP .com de las anteriores?
|
1 2 3 4 5 |
## ¿Cuántas peticiones ha habido a cada IP .com de las anteriores ## #Obtenemos las peticiones filtradas y ordenadas peticionesFiltradas <- dplyr::count(dsLog_Filtrado, ip, sort = T); #Mostramos las peticiones peticionesFiltradas; |
De las anteriores IP .com ¿cuántas peticiones ha habido agrupadas por código de retorno?
|
1 2 3 4 5 |
## De las anteriores IP .com ¿cuántas peticiones ha habido agrupadas por código de retorno? #Contamos los códigos de retorno numCodigoRetorno <- dplyr::count(dsLog_Filtrado, codigo_retorno); #Mostramos los valores obtenidos numCodigoRetorno; |

De las peticiones con código de retorno 100 ¿cuáles podrían tener un formato IP?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
## De las peticiones que reciben un código de retorno "100", ## ## obtener las que tienen direcciones con formato IP ## #Filtramos peticiones con código de retorno 100 peticionesIP100 <- dsLog[dsLog$codigo_retorno == "100", "ip"]; #Mostrar peticionesIP100; #Extraer las peticiones únicas peticionesIP100 <- unique(peticionesIP100); #Mostrar peticionesIP100; #Filtramos las que empiezan por número (suponemos que serán IP) ip100 <- dplyr::filter(peticionesIP100, grepl(pattern = "^[0-9]", x = ip)); #Mostrar ip100; #Contar el número de IP únicas nrow(ip100); |

Obtener datos de ubicación geográfica por cada IP de las obtenidas anteriormente en ip100: región, país y ciudad:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
## Obtener la localización geográfica de las IP anteriores ## usando http://ip-api.com/json/ ## #En primer lugar obtenemos sólo la IP de ip100 ipV <- ip100$ip; #Comprobamos el número length(ipV); #Creamos una función para obtener la región, país y ciudad de cada dirección IP #Se almacenará en un data frame, la función devolverá este data frame ubicacionGeografica <- function(lsIP) { dfIPUbicacion <- data.frame(ip = c(""), region = c(""), pais = c(""), ciudad = c(""), error = c("")); for (i in 1:length(lsIP)) { ipActual = as.character(lsIP[i]); #Una IPv4 tiene al menos 7 caracteres if (nchar(ipActual) > 6) { tryCatch({ #Montamos la URL con formato http://ip-api.com/json/IP urlIPACtual <- paste('http://ip-api.com/json/', ipActual, sep = ''); #Usamos fromJSON para obtener valores JSON ubicacionIPActual <- fromJSON(readLines(urlIPACtual, warn = FALSE)); #Asignamos cada valor a su correspondiente del data frame dfIPUbicacion[i,]$ip <- ipActual; dfIPUbicacion[i,]$region <- ubicacionIPActual$regionName; dfIPUbicacion[i,]$pais <- ubicacionIPActual$country; dfIPUbicacion[i,]$ciudad <- ubicacionIPActual$city; dfIPUbicacion[i,]$error <- "OK"; }, error = function(e) { #Ha habido algún error al obtener la ubicación #Para depurar, mostrar el error #print(paste(ipActual, e, sep = "->"; dfIPUbicacion[i,]$ip <- ipActual; dfIPUbicacion[i,]$region <- ""; dfIPUbicacion[i,]$pais <- ""; dfIPUbicacion[i,]$ciudad <- ""; dfIPUbicacion[i,]$error <- e}); #Esperamos 1 segundo entre cada petición #Para no generar tráfico excesivo y no ser baneados Sys.sleep(1); } else { #IP incorrecta dfIPUbicacion[i,]$ip <- ipActual; dfIPUbicacion[i,]$region <- ""; dfIPUbicacion[i,]$pais <- ""; dfIPUbicacion[i,]$ciudad <- ""; dfIPUbicacion[i,]$error <- "IP incorrecta"; } } #Devolvemos el data frame con el resultado de cada IP return(dfIPUbicacion); } #Usamos la función anterior para obtener en un data frame los datos #de geolocalización de cada IP del ipV #Tardará un segundo por cada IP al menos dfIPconLocalizacion <- ubicacionGeografica(ipV); #Mostramos el resultado dfIPconLocalizacion; |
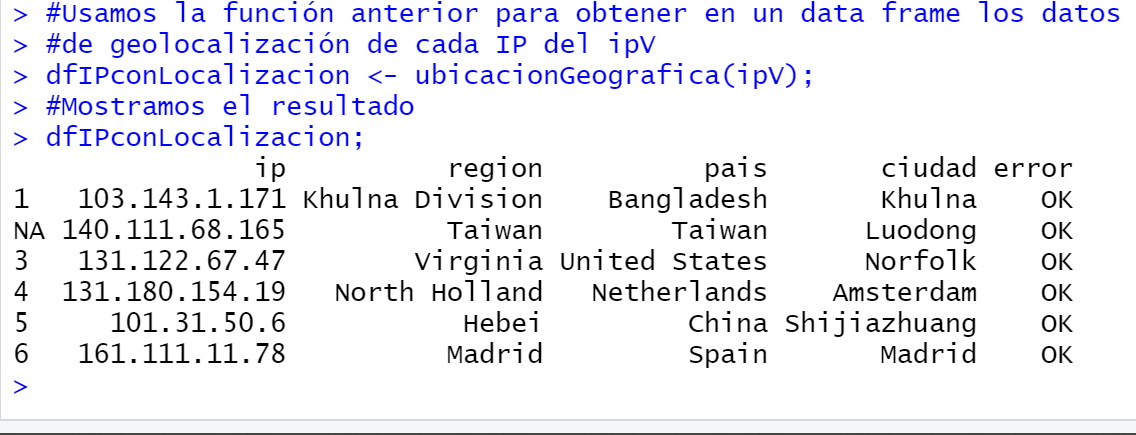
Del total de peticiones hechas por dominio .com, ¿Cuántos bytes en total se han transmitido en peticiones de descarga de ficheros de tipo «.gif»?
|
1 2 3 4 5 6 7 8 |
## Del total de peticiones hechas por dominio .com, ## ## ¿Cuántos bytes en total se han transmitido en peticiones de descarga de ficheros de tipo ".gif"? ## #Filtramos las ip con dominio .com dsIPCOM <- dplyr::filter(dsLog, grepl(pattern = ".com", x = ip)); #Filtramos los registros cuyo campo url acabe en .gif dsIPCOMGIF <- dplyr::filter(dsIPCOM, grepl(pattern = ".gif$",x = url)); #Sumamos el campo tamano_respuesta del dataset anterior para obtener el total de bytes sum(dsIPCOMGIF$tamano_respuesta, na.rm = T); |

¿Cuántas peticiones buscan directamente la URL = «/robots.txt» en todo el dataset?
|
1 2 3 4 5 6 7 |
## ¿Cuántas peticiones buscan directamente la URL = "/robots.txt" en todo el dataset? #Filtramos las peticiones que solicitan la url /robots.txt dsRobots <- dplyr::filter(dsLog, url == "/robots.txt") #Mostrar resultado dsRobots; #Contar filas nrow(dsRobots); |

¿Cuántas peticiones NO tienen como protocolo «HTTP/1.0»?
|
1 2 3 4 5 6 7 |
## ¿Cuántas peticiones NO tienen como protocolo "HTTP/1.0"? ## #Filtramos las peticiones con protocolo distinto de HTTP/1.0 dfProtocoloHTTP1 <- dplyr::filter(dsLog, protocolo != "HTTP/1.0\""); #Mostramos resultado dfProtocoloHTTP1; #Número de filas nrow(dfProtocoloHTTP1); |

Descarga del código R completo y fichero de log de ejemplo
A continuación mostramos enlace para la descarga del código R completo y funcional (Tratamiento_Log.R) con todos los ejemplos de este artículo, incluyendo el fichero de log de accesos utilizado (log_http.csv):




{kind=link}