Cómo desplegar un clúster de Docker real (en producción) con varios nodos usando Docker Swarm. Cómo desplegar un servicio en varios de los nodos del clúster para alta disponibilidad.
- Requisitos para montar clúster real Docker con Swarm.
- Qué es Docker Swarm.
- Despliegue de un clúster Docker con Docker Swarm.
- Añadir un segundo nodo manager (master) al clúster Swarm.
- Publicar una aplicación web Nginx y PHP en el clúster Swarm.
- Publicar Portainer en clúster Swarm para gestionar gráficamente el clúster.
Requisitos para montar clúster real Docker con Swarm
Necesitaremos disponer de un entorno de virtualización con varias máquinas virtuales con Linux o bien de servidores físicos, suficientes para montar el clúster, al menos dos o tres. El sistema operativo de estos servidores (sean virtuales o físicos) será Linux Ubuntu Server (es válida cualquier otra distribución de Linux).
Recomendamos usar distribuciones relativamente ligeras, que no incorporen modo gráfico, dado que necesitaremos todos los recursos de CPU, RAM y almacenamiento posibles para uso de los contenedores Docker.
Por lo tanto, partiremos de dos o tres equipos con Linux Ubuntu Server 22 instalado. En estos equipos instalaremos Docker Engine, como indicamos en este artículo:
Básicamente, para instalar Docker Engine en un equipo con Linux Ubuntu, ejecutaremos los siguientes comandos:
|
1 2 3 4 5 6 7 8 9 10 11 |
sudo apt-get update sudo apt-get install ca-certificates curl gnupg sudo install -m 0755 -d /etc/apt/keyrings curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg sudo chmod a+r /etc/apt/keyrings/docker.gpg echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin |
Por lo tanto, en nuestro entorno de virtualización tendremos, al menos, tres equipos con Linux Ubuntu (u otra distribución), con Docker Engine instalado y, a ser posible y como recomendación para alta disponibilidad, los nodos deben estar en servidores ESX diferentes, incluso alguno en ubicaciones diferentes.

En este despliegue, los equipos tendrán el siguiente nombre DNS e IP:
- srvdockernodo1: 192.168.1.70 [Master_1] [Worker_1].
- srvdockernodo2: 192.168.1.68 [Master_2] [Worker_2].
- srvdockernodo3: 192.168.1.69 [Worker_3].
Estableceremos dos nodos master y los tres serán workers, dado que Swarm permite que los nodos master también puedan ser workers. Y, por disponibilidad, se recomienda encarecidamente que haya dos o más nodos master en el clúster.
Nota importante: en este despliegue no se establecerá el almacenamiento de alta disponibilidad. Por lo que los servicios y contenedores que se publiquen en el clúster Swarm no tendrán alta disponibilidad a nivel de almacenamiento. Por ejemplo, si desplegáramos un contenedor con MySQL o MariaDB, los ficheros de la base de datos se almacenarían en un volumen del contenedor únicamente en el nodo donde se hubiera desplegado. Si este nodo cae, los datos no se «replican» en el resto.
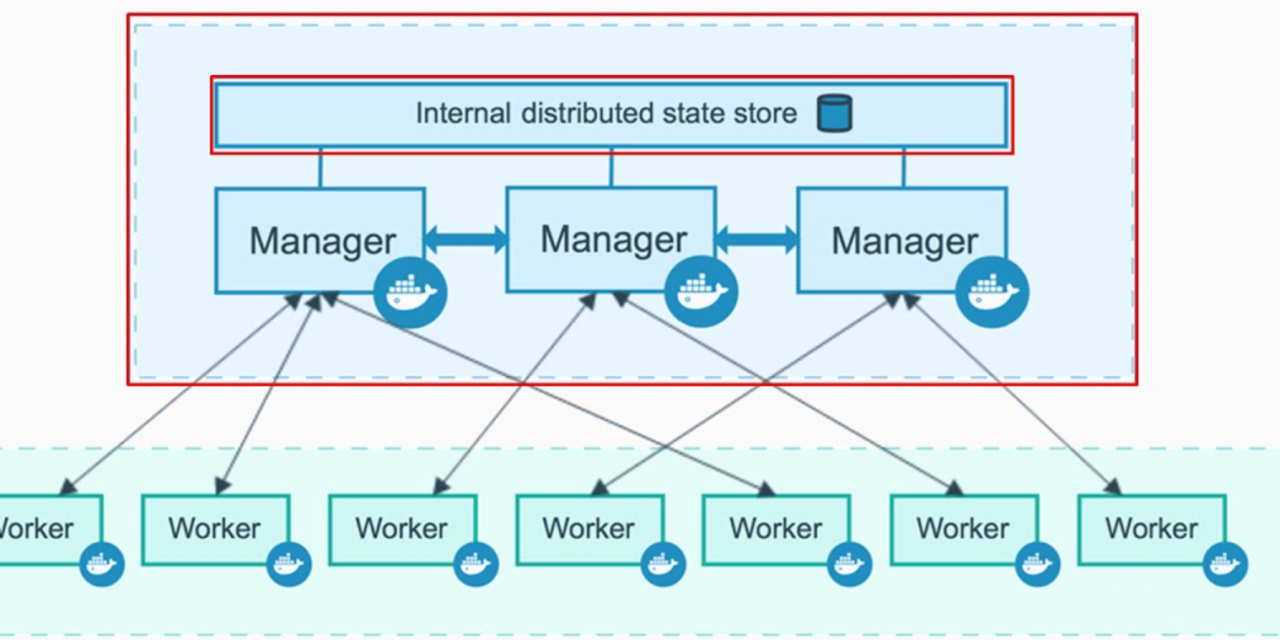
Qué es Docker Swarm
Docker Swarm es una herramienta incorporada por Docker a su entorno para gestionar un grupo de equipos con Docker Engine. Swarm es, simplificando, la herramienta para montar un clúster Docker en producción. De forma que podamos tener nuestros contenedores corriendo en varios servidores (sean físicos o virtuales). Así, si cae un servidor de la granja, el contenedor seguirá funcionando en otro de los servidores nodo del clúster.
Para administrar un Swarm se utiliza Docker Engine CLI, por lo que no se necesita instalar ningún software adicional.
Algunas de las características de Swarm:
- Descubrimiento de servicios: para cada servicio que se ejecuta se asigna un nombre DNS único utilizando un servidor DNS embebido en Swarm.
- Balanceo de carga: se pueden exponer los puertos de los servicios a un balanceador de carga externo. Swarm permite definir cómo distribuir la carga de los servicios entre los nodos.
- Seguro por defecto: Swarm utiliza TLS para la autenticación y encriptación de la comunicación entre los nodos, permitiendo la opción de utilizar certificados auto-firmados o de una CA personalizada.
- Diseño descentralizado: la diferenciación de los roles dentro del clúster se realiza en tiempo de ejecución, por lo que lo podremos utilizar la misma imagen para los diferentes roles.
- Modelo declarativo: utiliza un modelo declarativo para describir los servicios.
- Escalado: por cada servicio se puede indicar el número de tareas o instancias a ejecutar. La gestión es automática, tanto del aumento como de la reducción del número de instancias por servicio.
- DSC: el nodo de gestión monitoriza constantemente el estado del clúster y los nodos para corregir posibles desviaciones del estado deseado declarado.
- Red multi-host: Swarm permite crear una red para los servicios que es común para todos los hosts (overlay network).
Al trabar con Swarm, es importante tener en cuenta los siguientes términos:
- Orquestación: describe el flujo para desplegar aplicaciones relacionadas entre sí.
- Swarm: es un clúster de Docker Engine, también llamados nodos, donde se desplegarán servicios. El cliente de Docker incluye comandos para administrar nodos (añadir o eliminar) y para desplegar y orquestar servicios a través de dichos nodos.
- Nodo: es una instalación de Docker Engine en un equipo (físico o virtual) que participará en el clúster Swarm. En entornos de producción habrá diferentes nodos separados en distintos servidores y en diferentes localizaciones.
- Nodo administrador (manager node, nodo maestro): es el encargado de repartir las tareas a los nodos de trabajo.
- Nodo de trabajo (worker node): recibe y ejecuta tareas repartidas por el nodo administrador.
- Servicios: se trata de tareas a ejecutar en un nodo de trabajo. Un servicio contiene la imagen a utilizar y los comandos a ejecutar dentro de los contenedores. En resumen, un servicio Swarm es un contenedor de Docker. Existen dos tipos de servicios:
- Global services: se replicarán el todos los nodos workers del clúster.
- Replicated services: se replicarán en algunos nodos workers, de forma aleatoria.
- Tareas: son comandos a ejecutar dentro de un contenedor específico.
- Balanceador de carga (load balancing): el administrador de Swarm utiliza un balanceador de carga de conexiones entrantes para exponer los servicios deseados de forma pública. A través de un DNS interno, automáticamente, balanceará la carga a los contenedores de un servicio.
- Stacks en Docker Swarm: son definiciones en un archivo de texto en formato YAML de múltiples servicios, volúmenes y redes. Con estos ficheros se permite iniciar múltiples contenedores y los elementos que necesiten para su funcionamiento. Los stacks son el equivalente para Docker Swarm de los archivos multicontenedor de Docker Compose y el formato entre ambos es similar.
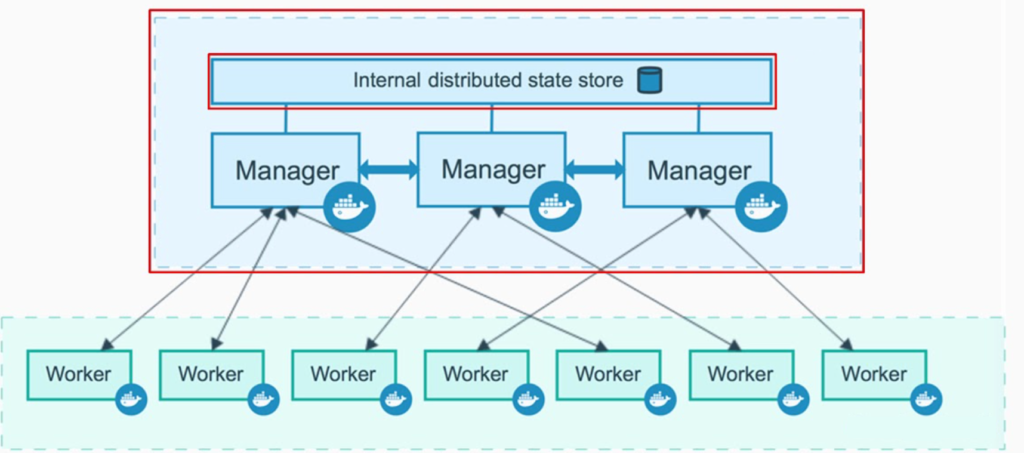
Despliegue de un clúster Docker con Docker Swarm
En el caso de Swarm, a diferencia de Kubernetes, el proceso de despliegue del clúster es bastante sencillo. En nuestro entorno de producción disponemos de tres equipos con Linux, escogeremos cuál de ellos será el master (maestro). Accederemos a su shell de comandos e introduciremos el siguiente comando para desplegar el clúster Docker y hacerlo como maestro:
|
1 |
docker swarm init --advertise-addr 192.168.1.70 --default-addr-pool 172.81.0.0/16 |
En el caso anterior, hemos indicado a Swarm que la red que se usará para la interconexión entre los nodos será la 172.81.0.0/16. En cada caso se elegirá la red que se desee. Si no se incluye el parámetro default-addr-pool, Swarm establecerá la red de defeco 10.0.0.0/24. También hemos indicado cuál es la IP del equipo que será master, donde ejecutamos el comando, que para este caso, es el equipo srvdockernodo1, con IP 192.168.1.70.

Como vemos en la salida del comando anterior, nos genera un comando con el token para añadir un worker, que será:
|
1 |
docker swarm join --token SWMTKN-1-114uhaztf6v1dr11qo4o0jo4msktsq0tp7z4w0a10ilp7weghp-0mfynnthe4s7rqib5mfi346sf 192.168.1.70:2377 |
Si nos vamos al shell de comandos del equipo Linux srvdockernodo2 (con IP 192.168.1.68) y ejecutamos el comando anterior, veremos que lo agrega al clúster Swarm Docker automáticamente como worker:

Nos mostrará el mensaje: This node joined a swarm as a worker. Indicando que el nodo ha sido añadido al clúster Swarm como worker.
Para generar de nuevo el comando con el token para añadir un nuevo nodo worker al clúster, desde el nodo master (srvdockernodo1), ejecutaremos el comando docker:
|
1 |
docker swarm join-token worker |

Generará de nuevo el comando con el token, que copiaremos y ejecutaremos en el tercer nodo (srvdockernodo3), convirtiéndolo en otro worker para el clúster:

Desde el nodo master (srvdockernodo1), podremos listar todos los nodos que componen el clúster, con el comando docker:
|
1 |
docker node ls |

En la columna «MANAGER», indicará cuál es el master, con la palabra «Leader».
Añadir un segundo nodo manager (master) al clúster Swarm
Para añadir un nuevo nodo master al clúster (lo recomendable es tener dos o más master), desde el nodo master actual (srvdockernodo1), ejecutaremos el comando docker:
|
1 |
docker swarm join-token manager |

Al igual que para el nodo worker, generará el comando completo con el token para ejecutar en un equipo con Docker Engine que convertiremos en nodo master. En nuestro caso, añadiremos un segundo master en el nodo srvdockernodo2. En este caso, puesto que el nodo 2 ya lo hemos convertido en worker, tendríamos que desconectarlo de nodo worker, ejecutando el comando, en el shell del nodo2 (srvdockernodo2):
|
1 |
docker swarm leave |
Esto no hay que hacerlo si el nodo no ha sido convertido a worker.
Ahora podremos ejecutar el siguiente comando para convertirlo en master:
|
1 |
docker swarm join --token SWMTKN-1-114uhaztf6v1dr11qo4o0jo4msktsq0tp7z4w0a10ilp7weghp-6bpw9dnn3rrdrdbp7k344kl41 192.168.1.70:2377 |

A partir de ahora, desde cualquier de los dos nodos master, podremos ejecutar el siguiente comando para listar todos los nodos del clúster:
|
1 |
docker node ls |
Nos mostrará todos los nodos del clúster, y el estado:

Comprobaremos que el master 2 (srvdockernodo2) está en estado «Reachable» y el master 1 (srvdockernodo1) queda como primario «Leader».
Dado que Docker Swarm permite que los nodos masters también sean workers, en nuestro despliegue tendremos 3 nodos workers, para servir contenedores y dos masters para alta disponibilidad. En el caso de orquestaciones con Kubernetes, por el contrario, los nodos masters no pueden ser workers. Por lo tanto, en este estudio de caso, tendríamos que añadir dos equipos Linux exclusivos como masters y añadir otros tres más como nodos workers, teniendo un total de cinco equipos.
Publicar una aplicación web Nginx y PHP en el clúster Swarm
Como ejemplo, vamos a desplegar un par de contenedores con Nginx y PHP. Para ello, seguiremos los pasos de este tutorial:
Seguiremos las instrucciones del tutorial anterior, añadiendo dos ficheros compose.yaml y cf.cnf en una carpeta. Una vez creados estos ficheros, con su contenido, desde dicha carpeta, ejecutaremos el siguiente comando para desplegar la aplicación web que llamaremos «web»:
|
1 |
docker stack deploy --compose-file compose.yaml web |

Para listar los contenedores publicados en el clúster, ejecutaremos, en el shell del master:
|
1 |
docker ps |

Para mostrar los servicios creados en el clúster Swarm, así como el estado de réplica, ejecutaremos el comando:
|
1 |
docker service ls |

De momento, no hemos escalado la aplicación web para que se despliegue en varios nodos, por ese motivo, en la columna «Replicas», muestra el valor 1/1.
Para comprobar que el servidor web desplegado en el clúster funciona desde cualquiera de los tres nodos, añadiremos el fichero index.php (como indicamos en el tutorial anterior), previamente necesitaremos instalar nano en el contendor, con el comando:
|
1 |
docker exec -it web_web.1.6wyd9aycuhef6ajakx7lnsrwf bash -c 'apt-get -y update && apt -y install nano' |
(Cambiaremos el nombre del contendor web_web.1.6wyd9aycuhef6ajakx7lnsrwf por el que haya asignado en cada despliegue)
Una vez instalado nano en el contenedor, ejecutaremos este otro comando para añadir el fichero index.php:
|
1 |
docker exec -it web_web.1.6wyd9aycuhef6ajakx7lnsrwf bash -c 'nano /var/www/html/index.php' |
Añadiremos el siguiente contenido de ejemplo, que mostrará una página con datos de la instalación de Nginx y PHP:
|
1 2 3 |
<?php echo phpinfo(); ?> |

Si ahora accederemos a cualquiera de los tres nodos del clúster Swarm, ejecutando las URL siguientes desde un navegador web de cualquier equipo de la red:
- http://192.168.1.70:8080
- http://192.168.1.68:8080
- http://192.168.1.69:8080
En los tres casos mostrará el mismo sitio web, correspondiente al contendor con Nginx y PHP desplegado en el clúster:
Escalar servicio a varios nodos del clúster Swarm
Para escalar un servicio a más de un nodo del clúster, para que se despliegue en varios nodos y así, si cae uno de los nodos, el servicio seguirá en funcionamiento desde otro nodo (alta disponibilidad), ejecutaremos el siguiente comando en el shell de comandos de uno de los nodos master:
|
1 |
docker service scale web_web=2 |
El comando anterior desplegará el servicio «web_web» (contenedor con servicio web Nginx) en dos nodos del clúster:

Repetiremos el proceso para escalar a dos nodos el servicio «web_php-fpm» (contenedor con PHP):
|
1 |
docker service scale web_php-fpm=2 |
Si listamos ahora los sevicios, podremos comprobar que web_web y web_php-fpm» están ahora en dos nodos:

Se puede, por supuesto, reducir el escalado, por ejemplo, el servicio web_php-fpm, dejarlo a un nodo únicamente:

El proceso de escalado se hace en caliente y no afectará a la disponibilidad del servicio.
Publicar Portainer en clúster Swarm para gestionar gráficamente el clúster
Portainer es una aplicación que permite gestionar gráficamente (entorno web) un clúster Swarm, también sirve para Kubernetes. Tiene un modo gratuito con limitación de tres contenedores máximo. Para usarla, en primer lugar, deberemos registrarnos en su web oficial y obtener la licencia gratuita.
Para desplegar Portainer en el clúster Swarm, desde el shell del nodo master, crearemos una carpeta llamada «portainer» (por ejemplo), accederemos a ella y descargaremos el fichero portainer-agent-stack.yml de la web oficial, con el comando:
|
1 |
curl -L https://downloads.portainer.io/ee2-19/portainer-agent-stack.yml -o portainer-agent-stack.yml |
Para desplegar Portainer en el clúster, al igual que hemos desplegado la aplicación web de ejemplo anterior, ejecutaremos el siguiente comando docker, desde la carpeta creada anteriormente «portainer» que contiene el fichero descargado portainer-agent-stack.yml:
|
1 |
docker stack deploy -c portainer-agent-stack.yml portainer |
Si listamos los servicios creados, veremos los servicios Docker Swarm portainer_agent y portainer_portainer, creados en el despliegue anterior. El servicio portainer_agent se crean en modo «global», lo que implica que se esclará y desplegará en todos los nodos del clúster. Por ello, en la columna «Replicas», aparece con el valor 3/3:

Si accedemos a cualquiera de los nodos, por el puerto 9443 y HTTPS, por ejemplo a:
https://192.168.1.70:9443
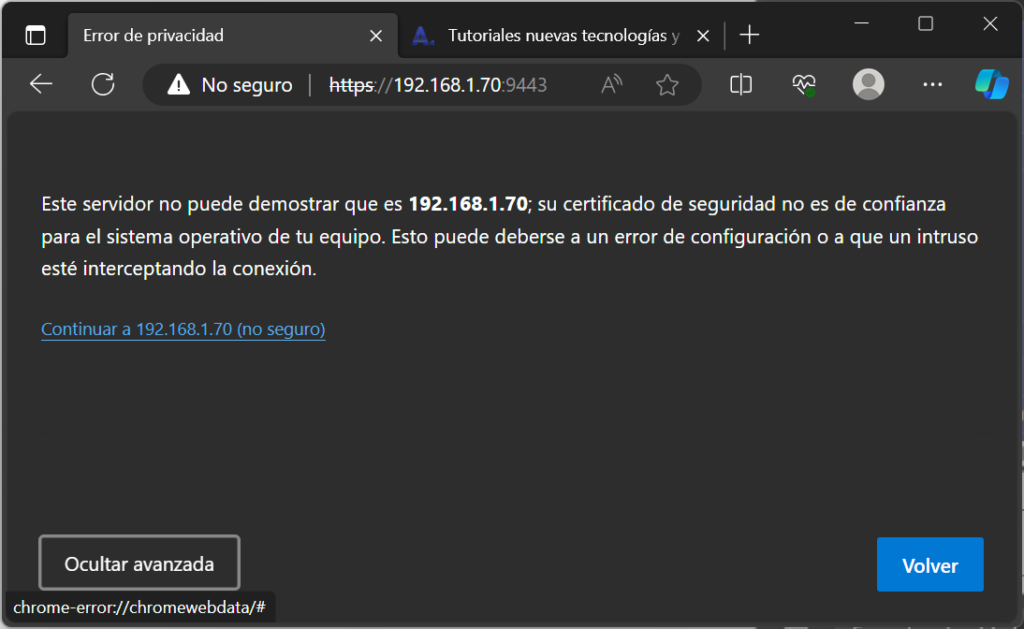
Nos cargará la web de Portainer. Pulsaremos en «Avanzado»:

Pulsaremos en «Continuar a…»:
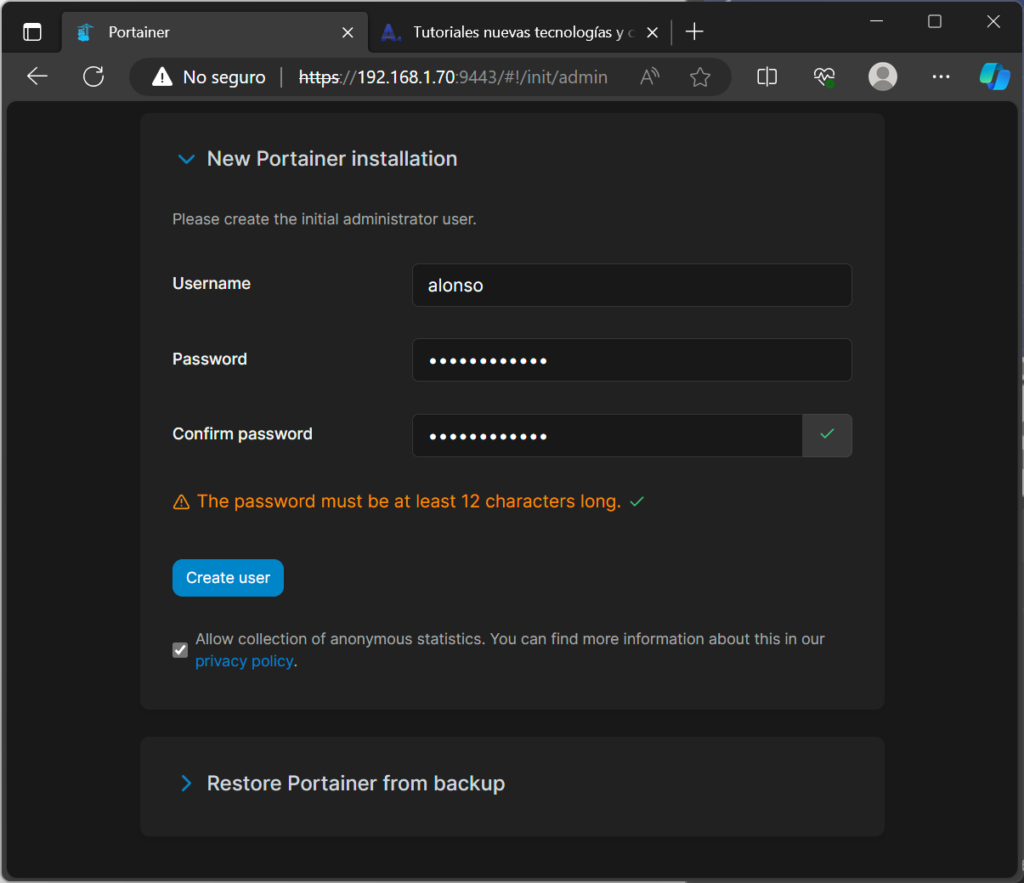
Introduciremos un usuario y contraseña que será el que se cree en este primer inicio y será con el que podamos iniciar sesión en Portainer:
Nos solicitará añadir la clave de licencia, que habremos recibido en nuestro correo electrónico.
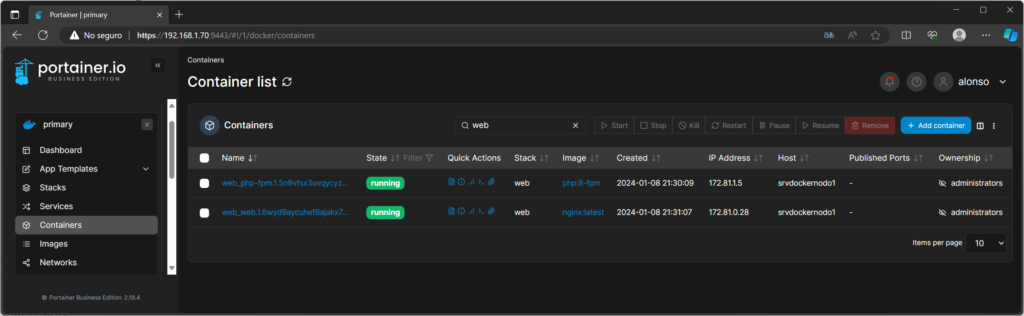
Y ya tendremos acceso a la gestión del clúster Swarm, de sus contendores, de sus nodos, servicios y toda su arquitectura:





{kind=link}